Self-Predict And Manual-Select For Improving LoRA-based Domain Fine-tuning
Self-Predict And Manual-Select For Improving LoRA-based Domain Fine-tuning
Abstract
LoRA fine-tuning preserves the information of the base LLMs while incorporating domain-specific data through fine-tuning. Therefore, if we use QA-pair domain training dataset to LoRA fine-tune a LLM and then employ this fine-tuned LLM to predict the domain training dataset itself, we can prepare two or more answers for each QA-pair’s question. We manually label the optimal answer from the answers, replace the original answer, and proceed to the next round of LoRA fine-tuning. Thus, we can continuously optimize the training dataset through iterative self-predict and human-select. This method can also be applied to multi-turn QA fine-tuning datasets. The human evaluation results of the fine-tuned LLM demonstrate that our approach is effective.
1. Introduction
In recent years, the development of large language models (LLMs) \cite{ref1,ref2,ref3} has brought breakthroughs on NLP applications.
2. Method
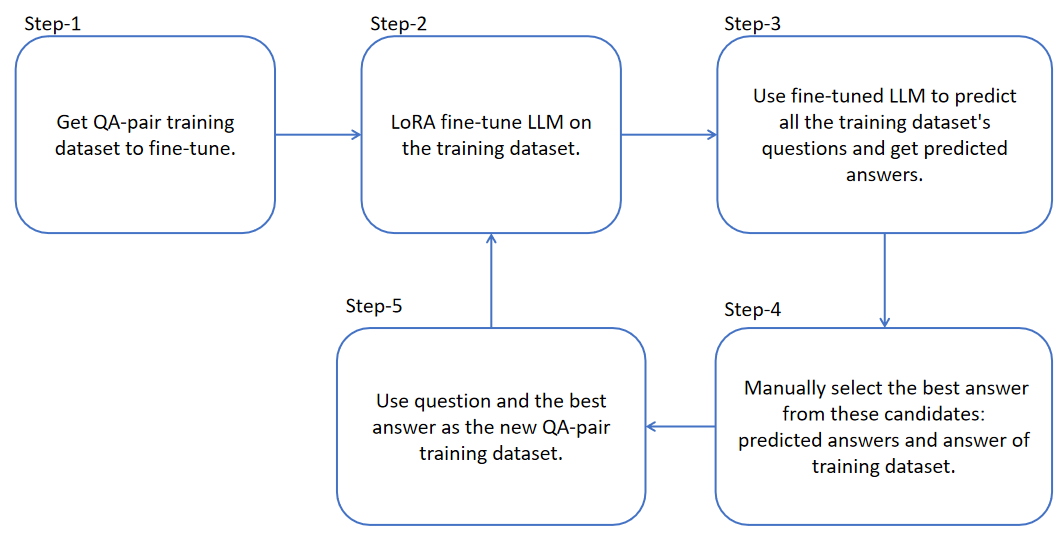
Reference
\bibitem{ref1}
Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
\bibitem{ref2}
Yang A, Li A, Yang B, et al. Qwen3 technical report[J]. arXiv preprint arXiv:2505.09388, 2025.
\bibitem{ref3}
Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.