Self-Refine Learning For Cleaning LLMs Data
Self-Refine Learning For Cleaning LLMs Data
Abstract
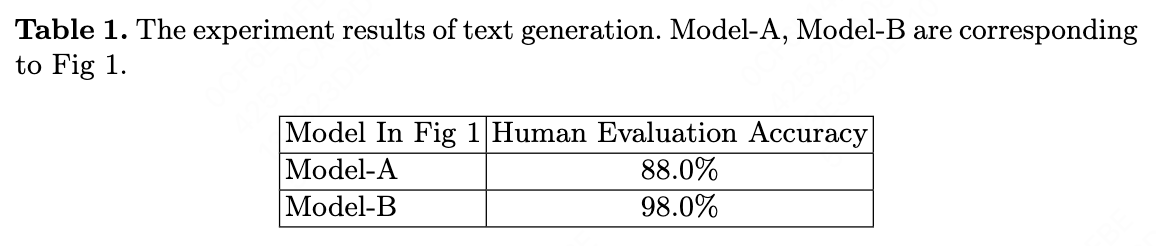
In industry NLP application, our dataset by prompting large language models (LLMs) has a certain number of noise data. We present a simple method to find the noise data and remove them. We retain the data that contains certain common tokens between the LLMs data and the prediction results of a generative model trained on the LLMs data. We remove the data that does not contain certain common tokens between the LLMs data and the prediction results of a generative model trained on the LLMs data. We adopt T5-Base as our generative model. The experiment result shows our method is highly effective and does not require any manual annotation. For industry deep learning application, our method improves the NLP tasks accuracy from 88% to 98% under human evaluation, meanwhile the LLMs data source is sufficiently abundant.
1. Introduction
With the development of LLMs \cite{ref1,ref2,ref3}, prompting LLMs to obtain a domain-specific training dataset and then training a smaller model to achieve sufficiently fast model inference has become a very useful approach for performing NLP tasks. However, the accuracy of LLMs’ original datasets within a specific domain generally only reaches 88%-90%. Additionally, using manual annotation methods to correct or clean the datasets requires a substantial amount of human resources and time. Therefore, this paper proposes a method for automatic dataset cleaning. Experiments show that it is highly effective, requires no manual annotation, and can be extended to more AI tasks based on LLMs datasets, such as computer vision.
2. Method
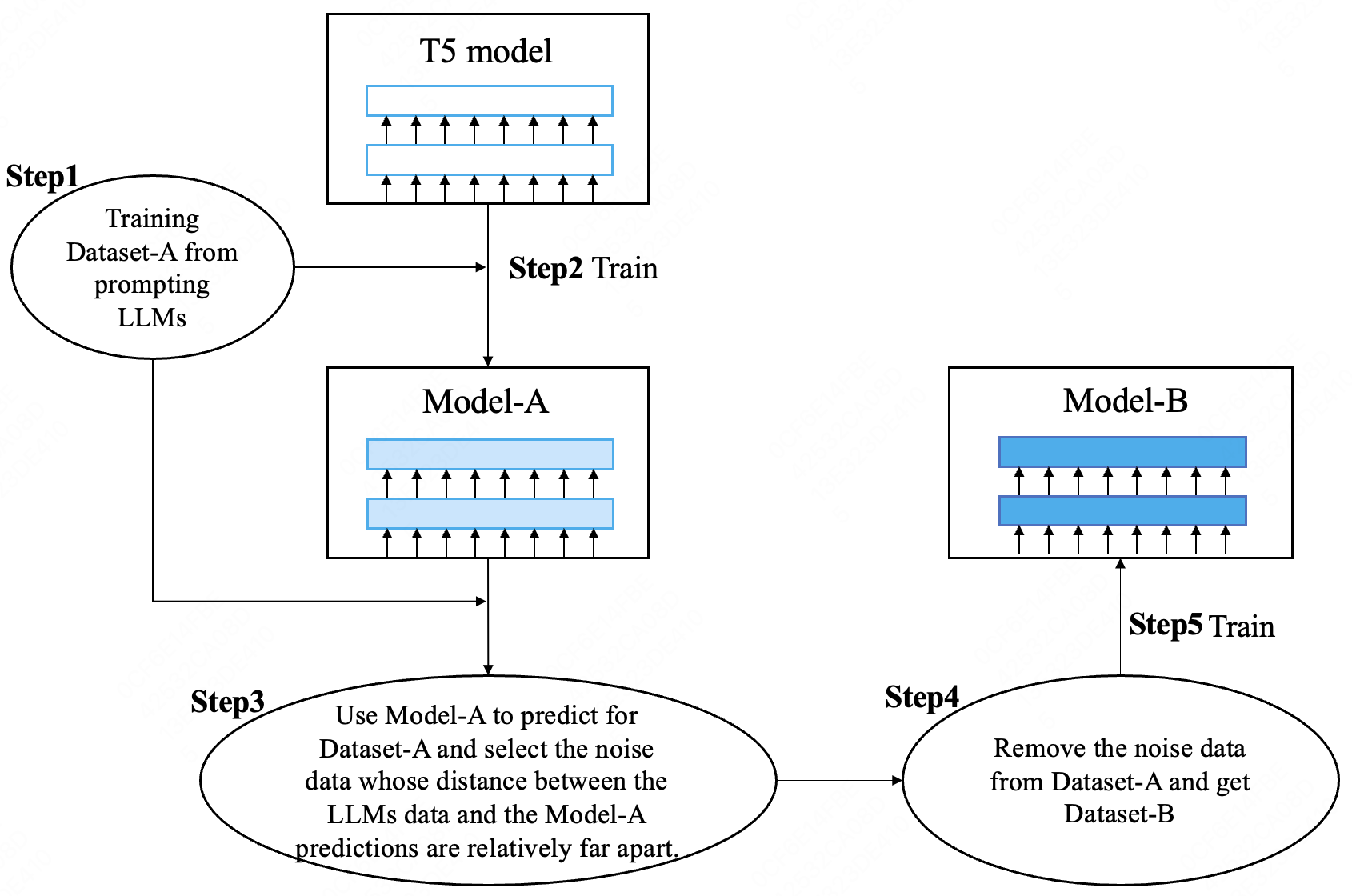
The whole pipeline and algorithm pseudocode of our method are shown in Figure \cite{fig1} and Algorithm \cite{alg1}. We conducted experiments on a NLP task that inputting item names to generate item tags. We prompted the LLMs to write synonyms for the item name that can be found through search.
In our task, the T5-Base model we trained overfitted on a dataset with a size of 50,000. We trained for 30-50 epochs. Our threshold condition is that the number of common tokens is greater than 20% of the total length of the two text data.

3. Experiment
We conducted experiments on a NLP task that inputting item names to generate item tags. We prompted the LLMs to write synonyms for the item name that can be found through search. We constructed an initial dataset of 50,000, which was reduced to 35,000 after being cleaned using our method.
The results of the experiment are shown in Table \cite{tab1}.
4. Discussion
In actual observations, we found that almost all noisy data with significant issues were filtered out. The significant issues here refer to the presence of unexpected special tokens in the data.
This automated cleaning method is a highly compatible combination with the method of obtaining data through prompting LLMs. The amount of training data obtained via prompting LLMs is sufficient, and we can set the necessary control thresholds to filter the data.
4.1 Comparing to RAG methods
Our approach is to obtain a dataset from LLMs to train our own model, in contrast to the RAG method \cite{ref6}, which involves working on the prompts given to LLMs.
For high-precision deep learning tasks, another approach is the RAG (Retrieval Augmented Generation) method, which involves providing more information to the prompts for LLMs. Upon observation, the issue with the RAG-LLM method is that some results returned by the LLMs are still uncontrollable and can be considered as noise for specific tasks.
5. Related Work
T5 \cite{ref4} is a model based on the transformer encoder-decoder architecture \cite{ref5}. In our experiments, we found that it performs better than the decoder-only GPT in single-turn question-answer style NLP (natural language processing) tasks.
6. Conclusion and Future Work
This paper proposes an automated, annotation-free method for cleaning dataset obtained from LLMs through prompting. In human evaluations, this method can increase accuracy from 88% to 98% in our NLP tasks. Additionally, this method can also be extended to other LLMs data-driven tasks, such as computer vision tasks.
Since we verify that using the methodology in this paper to clean LLM data enables effective training of a smaller model, applying this same approach to clean the complete post-training dataset originally used for training the LLM will become the direction we are to explore.
Reference
\bibitem{ref1}
Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
\bibitem{ref2}
Radford A. Improving language understanding by generative pre-training[J]. 2018.
\bibitem{ref3}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
\bibitem{ref4}
Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
\bibitem{ref5}
Vaswani A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017.
\bibitem{ref6}
Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.