Leveraging User Behaviour to Enhance LLMs for Query Analysis in E-commerce
Leveraging User Behaviour to Enhance LLMs for Query Analysis in E-commerce
Abstract
The advantage of using LLMs (Large Language Models) for query understanding is that we do not need to manually annotate data. But the problem with using LLMs for query analysis in e-commerce search is that the accuracy rate can at most reach up to 88%-90%, due to the lack of domain specific information. Meanwhile, based on mining query tags from user orders, the accuracy can reach over 95%. But the coverage rate of order-based query tags is ~50%, which is limited by the amount of user behavior logs, especially when the business scope is small. In this article, we propose a method for constructing training dataset for query understanding/tags, which combines the data by LLMs with the order-based data. Models trained on this dataset can achieve a coverage rate of over 95% and an accuracy rate of over 95% for query tagging.
1. Introduction
Query analysis, or query understanding \cite{ref3}, is the task of query tagging, such as query synonyms, query categories, etc. query understanding is a crucial part of the search system. In an e-commerce platform, search querys and user orders are closely linked, making it possible to mine search query tags based on user orders. At the same time, the emergence of LLMs (Large Language Models) \cite{ref1,ref2} allows for the possibility of returning desired search query tags based on customized prompts, potentially enhanced by additional auxiliary information from search results for the prompts.
The problem with prompting LLMs for query analysis in e-commerce search is that the accuracy rate can at most reach up to 88%-90%, due to the lack of domain specific information. At the same time, the coverage can exceed 95% because almost any input prompt containing query information given to LLMs will yield a result. The problem with order-based query analysis is that the coverage rate of the query tags is lower than 50%, with an accuracy greater than 95% that is usable. Therefore, this paper proposes a method for constructing a training dataset that combines the two approaches to train a model with a coverage rate of over 95% and an accuracy of over 95%.
2. Method
After cleaning the dataset by prompting the LLMs, combine it with the dataset mined based on user orders to obtain the final training dataset. The LLMs dataset and order-based dataset are constructed as follows:
2.1 Prompt LLMs for Query Analysis
We prompt LLMs to perform the task of query tagging. Then we clean the dataset.
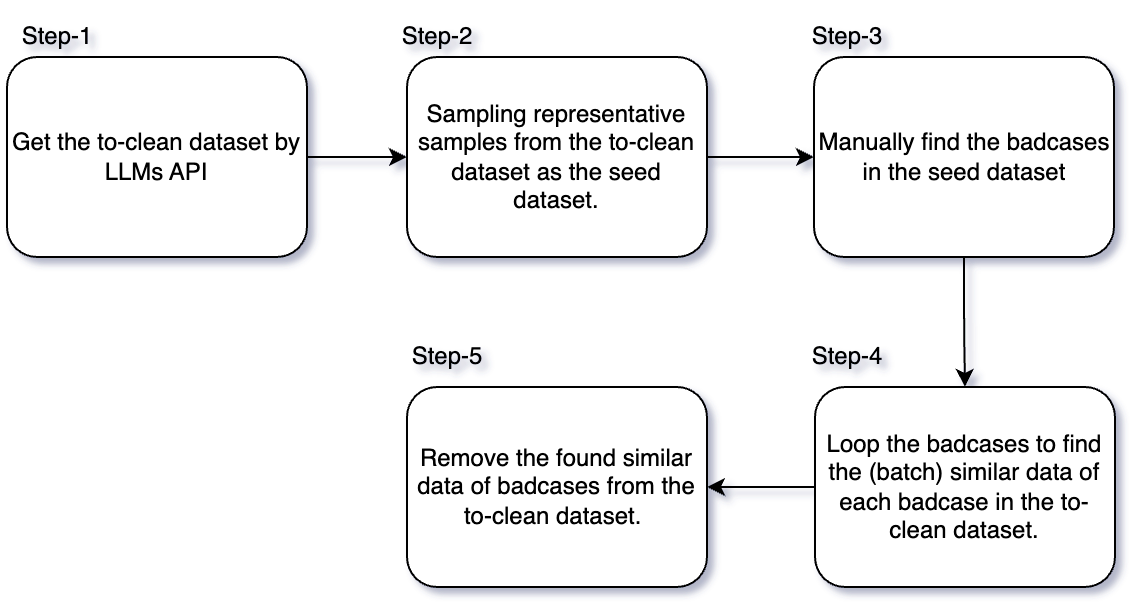
2.2 User Behaviour Based Query Analysis
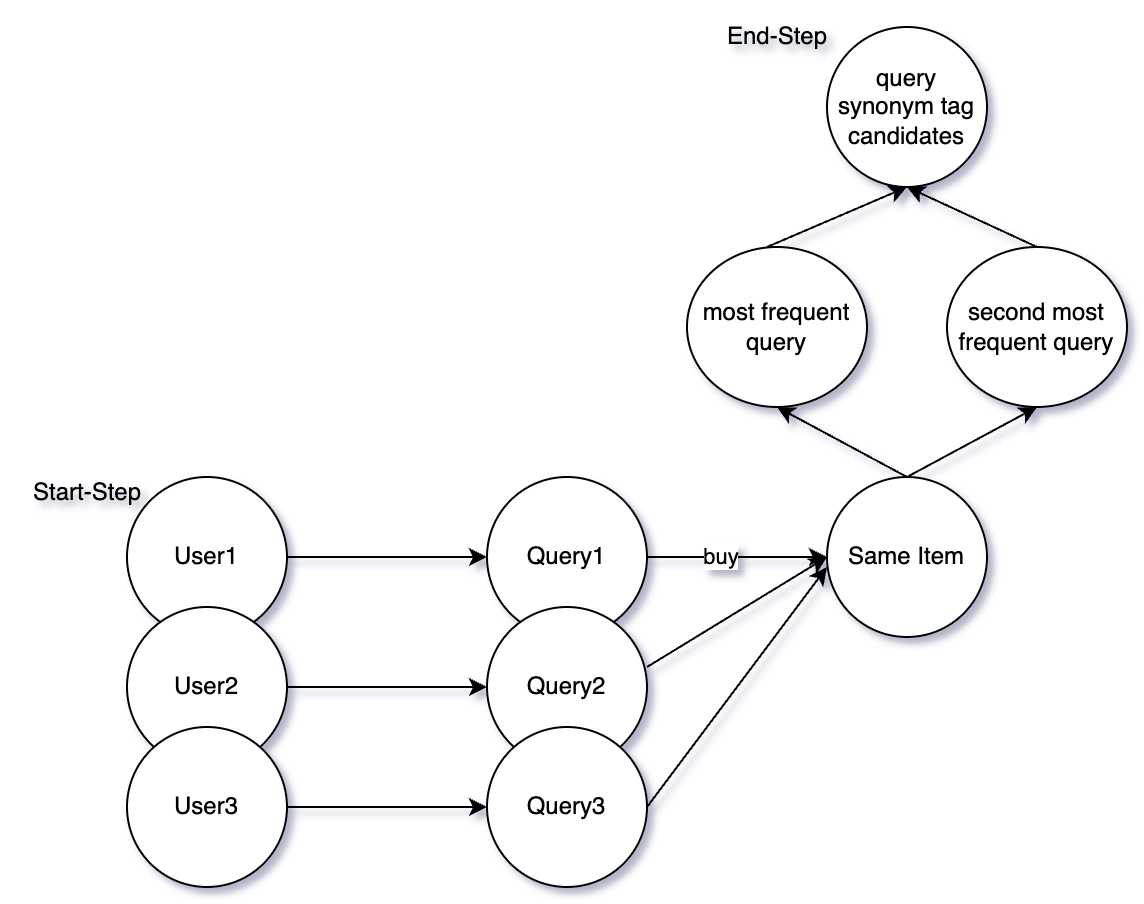
Count the item tags with the highest order amount within the same search query.
 Count the search querys with the highest and second highest amount of orders in the same item.
Count the search querys with the highest and second highest amount of orders in the same item.
2.3 Use Merged Dataset To Train
The final merged dataset has sufficient data quantity and quality to train a generative model that outputs tags for a given input query. Specifically, we used T5 \cite{ref4}. This T5 model performs tagging predictions for each query.
3. Experiments
Our T5 model trained on the final dataset achieves a coverage rate of over 95% and an accuracy rate of over 95% for query tagging.
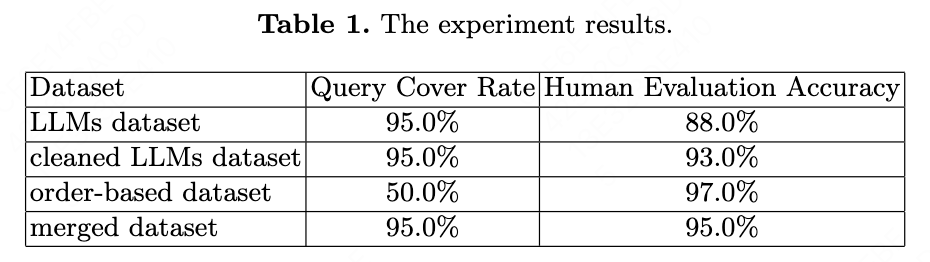
4. Discussion
There are many ways to merge the dataset from LLMs and the dataset based on orders:
1) Directly mix the order-based dataset and the cleaned LLMs dataset, if the accuracy of the LLMs dataset has also reached over 95%, considering the dataset based on orders already has an accuracy of over 95%.
2) If the prediction results for each query from the T5 model trained on order-based dataset are equal to those prediction from the LLMs, then append the training dataset with this data. If there is insufficient labeling manpower to perform the aforementioned LLMs data cleaning manually.
5. Related Work
T5 is a model based on the transformer encoder-decoder architecture \cite{ref5}. In our experiments, we found that it performs better than the decoder-only GPT in single-turn question-answer style NLP (natural language processing) tasks.
6. Conclusion
This paper proposes a method of constructing a training dataset using query tag mining based on user orders, while also integrating a dataset for query tagging from LLMs. The T5 model trained on the final dataset can achieve 95% coverage and 95% accuracy in query understanding.
Reference
\bibitem{ref1}
Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
\bibitem{ref2}
Radford A. Improving language understanding by generative pre-training[J]. 2018.
\bibitem{ref3}
Query understanding for search engines[M]. Heidelberg: Springer, 2020.
\bibitem{ref4}
Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
\bibitem{ref5}
Vaswani A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017.