Self-Eval-Drop for Cleaning LLMs Data
Self-Eval-Drop for Cleaning LLMs Data
Abstract
Leveraging large language models (LLMs) to performs direct inference or build training datasets has becoming an important method for natural language processing (NLP) applications. However the quality of the training datasets or inference results of LLMs exist some noise data. In this paper, we propose our self-eval-drop method to clean the datasets by LLMs API. We first sort the to-clean dataset by LLMs API and then sample a seed dataset from the to-clean dataset. Then we manually evaluate the seed dataset and find badcases in the seed dataset. Then we loop the badcases to find the (most) similar data in the to-clean dataset for each badcase. Then we remove the found similar data of badcases from the to-clean dataset. The manual evaluation results show that our simple self-eval-drop method can improve the accuracy of the to-clean dataset to more than 97% by only sampling and evaluating about 1% of the to-clean dataset as the seed dataset.
Keywords
Data Efficiency, Representative Sampling
1. Introduction
In recent years, the development of large language models (LLMs) \cite{ref1,ref3,ref4,ref5} has brought breakthroughs on NLP applications. However the quality of the training datasets or inference results of LLMs exist some noise data for the specific deep learning (DL) \cite{ref2} applications. In order to solve the noise data problem, we propose our self-eval-drop method to clean the datasets by LLMs API.
First, we identify suitable prompts to generate domain-specific data through LLM APIs, which can produce virtually unlimited data. Then programmers then either manually inspect the data (or assign it to annotators) and develop robust filtering rules to eliminate dirty data. This approach effectively enhances the quality of datasets derived from LLM APIs.
2. Method
The pseudo code is shown in algorithm \cite{alg1}. In this algorithm, the term “sort” refers to the process of arranging the text dataset in Unicode order, which we consider equivalent to sorting based on text similarity.

The whole pipeline is shown in figure \cite{fig1}. Our pipeline method has 5 steps:
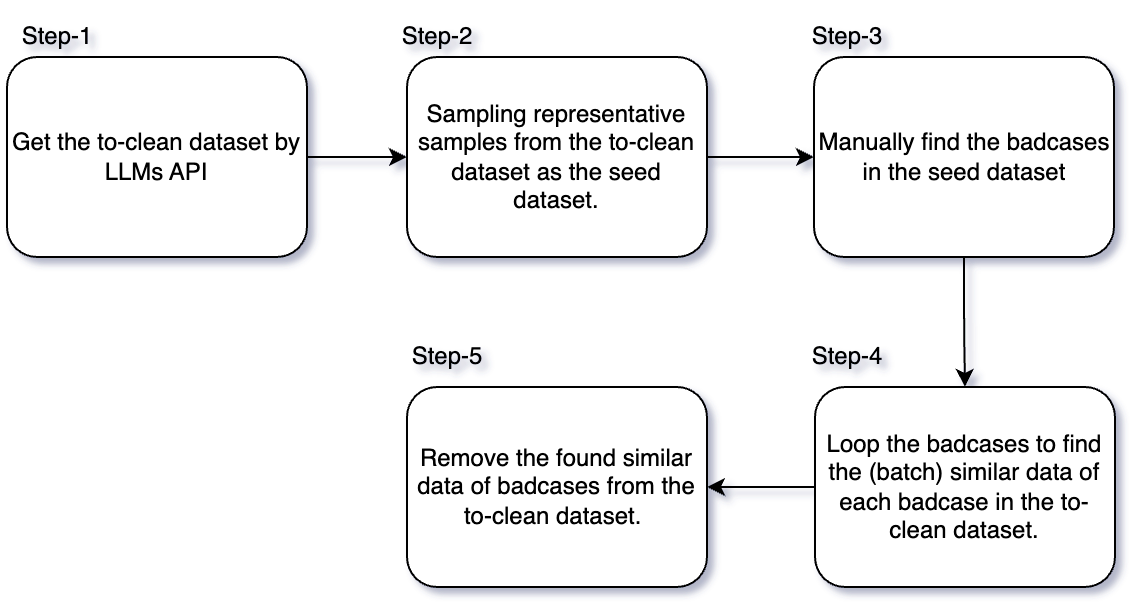
2.1 Prompt LLMs for Specific Problem
In order to solve our NLP problem, such as text generation, named entity recognition, we input the prompts to the LLMs and get the results as datasets.
2.2 Representative Sampling for Seed Dataset
In this step, to get the seed dataset that sample from the to-clean dataset, we should sample the representative data. In this paper, we sort the to-clean dataset by alphabetical order and sample 1 data every 100 data, when iterating sequentially.
2.3 Find Badcases in Seed Dataset
In this step, we manually evaluate the seed dataset. We find the badcases in the seed dataset.
2.4 Similar Data Search
In this step, we find the similar data in the to-clean dataset for each badcase in seed dataset, we define the two texts that contain the most common tokens as the most similar two texts.
2.5 Removing the Similar Data
In this step, we remove the searched similar data in the to-clean dataset by looping the badcases and get the cleaned dataset.
If we consider the data insufficient, we will return to Step-1.
3. Manual Evaluation
The manual evaluation results is shown in Table \cite{table1}.

4. Discussion
Prompt the LLMs to generate sufficient and diverse results, ensuring that the quantity of this data is both controllable and adequate. So, after removing some noisy data, the quantity of the remaining data is still adequate.
4.1 Motivation
The cost of annotation time is crucial for deep learning tasks based on manually labeled data. If there is not enough labeling manpower, we must find ways to reduce the amount of data that needs to be labeled. If we can reduce the amount of data to be labeled to a level that a single programmer can handle, then we do not need an additional labeling team.
Secondly, the number of calls to the large language models is sufficient, so the amount of data we can obtain is adequate. Therefore, the key issue is to improve the quality of the data.
4.2 About Prompt
Under the condition that the prompt itself is correct, the more content in the prompt, the more accurate LLMs’ response will be. The prompt is equivalent to the features of a model’s input. When training a model on your own, you also hope that, given the correctness of the features, the more features, the better. Covering various situations, you can even input the answer directly into the prompt for the LLMs.
4.3 Baseline Solution
If we manually review all the training data to identify and correct the error data, this method would consume a significant amount of annotation manpower.
5. Conclusion and Future Work
In order to solve the problem that the dataset by LLMs API has a certain number of noise data, we propose our method: First, we sample a seed dataset from the to-clean dataset by LLMs API. Then we manually find the badcases in the seed dataset. Then we search the to-clean dataset by querying the badcases to find the (most) similar data of the badcases in the to-clean dataset and remove the searched data. The manual evaluation results show that our simple self-eval-drop method can improve the accuracy of the to-clean dataset by LLM API to more than 97% by only sampling and manually evaluating about 1% of the to-clean dataset as the seed dataset.
Since we verify that using the methodology in this paper to clean LLM data enables effective training of a smaller model, applying this same approach to clean the complete post-training dataset originally used for training the LLM will become the direction we are to explore.
Reference
\bibitem{ref1}
Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
\bibitem{ref2}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25.
\bibitem{ref3}
Hadi M U, Qureshi R, Shah A, et al. Large language models: a comprehensive survey of its applications, challenges, limitations, and future prospects[J]. Authorea Preprints, 2023.
\bibitem{ref4}
Yang A, Yang B, Hui B, et al. Qwen2 technical report[J]. arXiv preprint arXiv:2407.10671, 2024.
\bibitem{ref5}
Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.