Improving Text Generation for Product Description via Human Behaviour
Improving Text Generation for Product Description via Human Behaviour
Abstract
Text generation serves as a crucial method for creating high-quality, available product descriptions from product titles. For the product description generation for online e-commerce applications, the primary challenge lies in enhancing the quality of generated text to boost app sales. This raises a fundamental question: how do we effectively evaluate text quality? When all generated texts are already positive and serviceable, it becomes inherently difficult to manually determine which version better serves a product’s purpose. Without reliable manual evaluation criteria, improving generated text quality remains unachievable. Since product descriptions in e-commerce aim to attract shoppers and drive sales, we developed a methodology that enhances text generation quality through analysis of user purchasing behavior. Our online experimental results demonstrate that this approach effectively increases product sales by optimizing text quality.
1. Introduction
In recent years, the development of deep learning (DL) has brought breakthroughs in text generation. The sequence to sequence (Seq2Seq) models use encoder-decoder transformer \cite{vaswani2017attention} for better model flexibility. The most representative models of this type include T5 \cite{raffel2020exploring} and BART \cite{lewis2020bart}. In this paper, we adopt the T5 \cite{raffel2020exploring} model to conduct our data-centric experiments.
In e-commerce, product descriptions can attract shoppers and improve sales. However, manually writing a successful product descriptions is highly time-consuming. Text generation \cite{zhang2022survey,prabhumoye2020exploring} technologies play a crucial role in this domain of applications.
Text generation involves an input (source sequence) $X$ and an output (target sequence) $Y$. In our product description generation tasks, $X$ represents the product title, $Y$ corresponds to the product description to be generated. Example pairs are illustrated in Table \cite{table1}.
The primary challenge involves enhancing the quality of generated text in e-commerce, which leads to a subsequent question: How do we define and evaluate what constitutes high-quality text for app sales? We find manual evaluation impractical for determining which text version better serves a product’s commercial objectives. To answer this problem, we define text that brings more sales to a product as better text. Thus, we employ user purchasing behavior data to objectively identify high-performing text variants.
This leads to a dual challenge: 1) Utilizing user purchasing behavior to identify higher-quality text, and 2) Isolating the text’s specific impact on product performance when displayed alongside the product.
In summary, to enhance generated product description quality, we must address these key challenges:
1) Human labeling cannot effectively determine which text version better improves app sales for products. Without reliable criteria to evaluate text quality (good vs. bad), optimization becomes unfeasible. Manual assessment can only verify whether text meets basic requirements for online display.
2) We employ user purchasing behavior as our quality metric, which necessitates isolating the text’s specific impact. This challenge arises because product descriptions are inherently coupled with their corresponding products during user exposure - both elements are simultaneously presented to shoppers.
3) A comprehensive solution must be developed to address these interdependent challenges systematically.
In this paper, we address these challenges through three key contributions:
1) Automated Quality Evaluation: We leverage user purchasing behavior to evaluate description effectiveness, overcoming the limitation of manual judgment for sales-optimized text.
2) Causal Impact Isolation: A sales prediction model trained on e-commerce transaction logs enables precise measurement of description quality through causal inference methods, disentangling textual impact from product-specific factors.
3) Closed-Loop Optimization: We implement an iterative system that continuously enhances generated descriptions using behavioral feedback, creating a self-improving mechanism for sales optimization.
2. Method
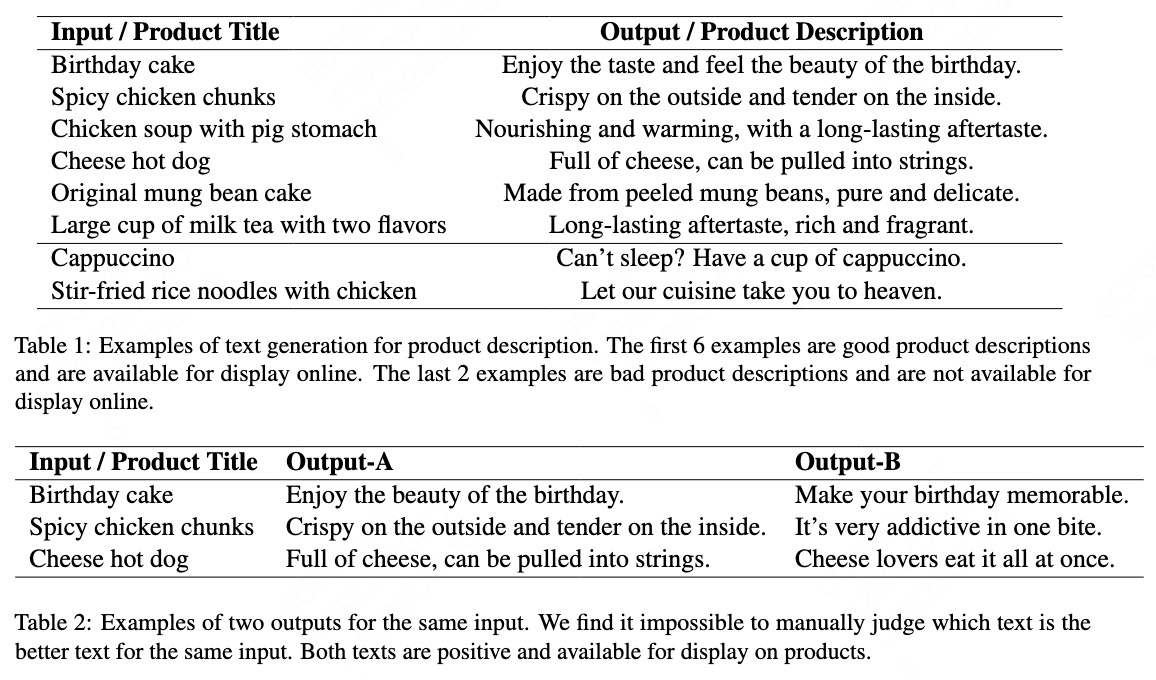
The whole pipeline is shown in Figure \cite{fig1}. In this paper, we adopt the T5 \cite{raffel2020exploring} model to conduct our text generation experiments. We adopt transformer \cite{vaswani2017attention} added multilayer perceptron (MLP) as our sales prediction model.
Our methodology comprises eight sequential stages:
In Step-1, Initial Dataset Construction. We obtain an initial dataset to train the T5 generative model. The dataset is constructed by querying ChatGPT to generate product descriptions, using product titles as prompts. We then remove data from the training dataset that are not suitable for online display. The detailed algorithm is shown in Algorithm \cite{alg1}.
In Step-2, Model Training \& Inference. Using the data from Step-1, we train the T5 model. The trained model is then used to generate product descriptions for hundreds of millions of products.
In Step-3, Deployment. We display the generated product descriptions for the products in the app.
In Step-4, Log Dataset Collection. We collect user purchase and view logs for each product.
In Step-5, Predictive Modeling. The sales prediction model is trained using logs from Step-4. Implementation details are described in the subsequent sections.
In Step-6 and Step-7, Causal Analysis. By combining causal inference with the sales prediction model, we identify the highest-quality product descriptions in the logs. Technical details are presented in subsequent sections.
In Step-8, Iterative Improvement. The T5 model is retrained using higher-quality texts identified in Step-7. AB testing is then conducted to evaluate the effectiveness of the generated product descriptions on the live app.
2.1 Initial Training Dataset Construction
This section corresponding to the Step-1 in Figure \cite{fig1}. We collect our initial training dataset by querying ChatGPT. Each prompt is formed by concatenating a product title. We ask ChatGPT to write descriptions for the products. We tried to add some product attributes as prompt, but most of the ChatGPT’s results do not relate to the product attributes. Table \cite{table1} shows the prompt examples and the ChatGPT’s results. Our T5 \cite{raffel2020exploring} model trained on this initial dataset gets 88\% available rate, under human evaluation.
2.2 Sales Prediction Model
When the generated product descriptions are deployed on the platform, user engagement (views and purchases) can be observed. This creates an opportunity to train a product sales prediction model. The training target is:
\[RPM = N_{sales} / N_{views}\]where $N_{sales}$ is the sales amount of product and $N_{views}$ is the viewed amount by users to this product.
The input features for the model include:
1) Product related features: product title, product tags, product history RPM.
2) Product description: Text tokens.
2.3 Training Target
The training objective is designed to quantify the incremental value added by textual product descriptions. Therefore, the sales prediction model optimizes the absolute value of RPM through a regression-based loss function.
\[allFeatures = concat(productFeatures, textTokens)\] \[modelOutput = model.forward(allFeatures)\] \[Loss = |productRPM - modelOutput|\]2.4 Causal Inference
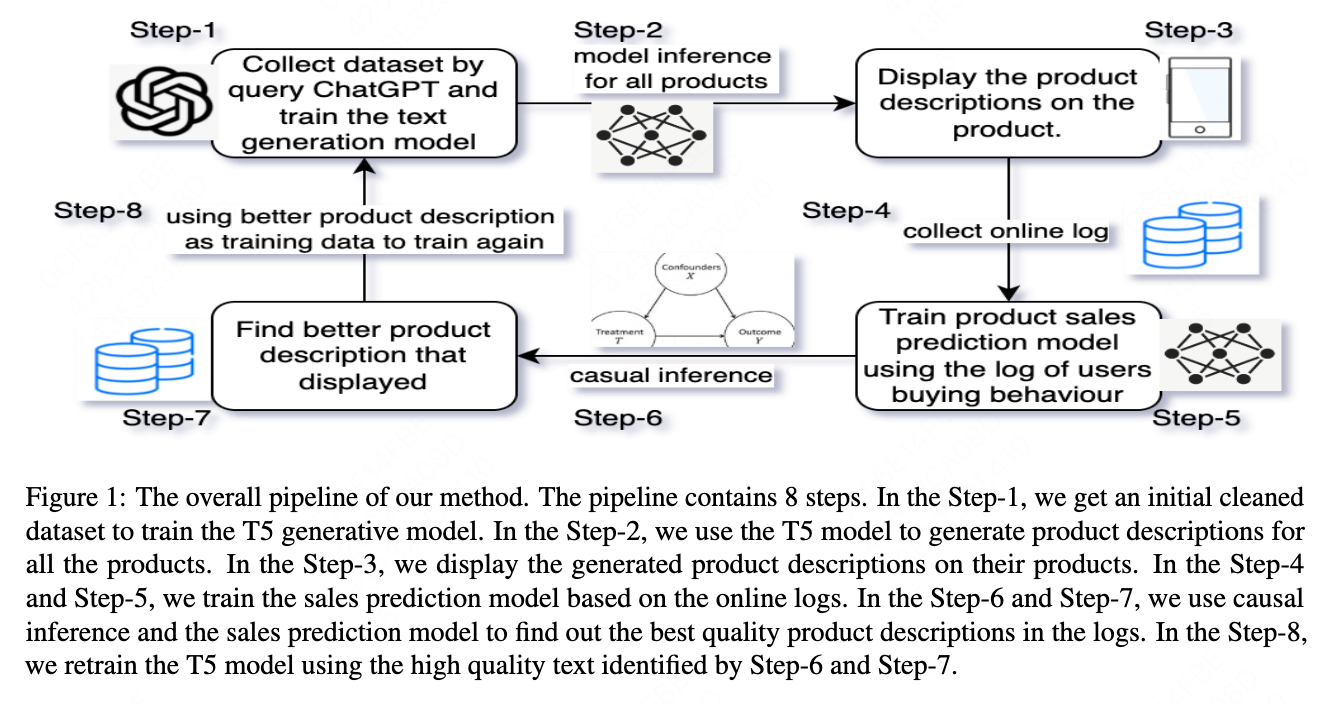
Causal inference in our framework serves to isolate the causal effect of product descriptions on sales, using the trained sales prediction model as a counterfactual estimator.
When we make a prediction, we input the product features and the text to get score $A$, and only the product features to get score $B$. The gain effect of the text for the product is $A-B$. The detail framework of sales prediction and causal inference is shown in Figure \cite{fig2}.
\[ScoreA = model.forward(productFeatures, textTokens)\] \[ScoreB = model.forward(productFeatures)\] \[TextQuality := ScoreA - ScoreB\]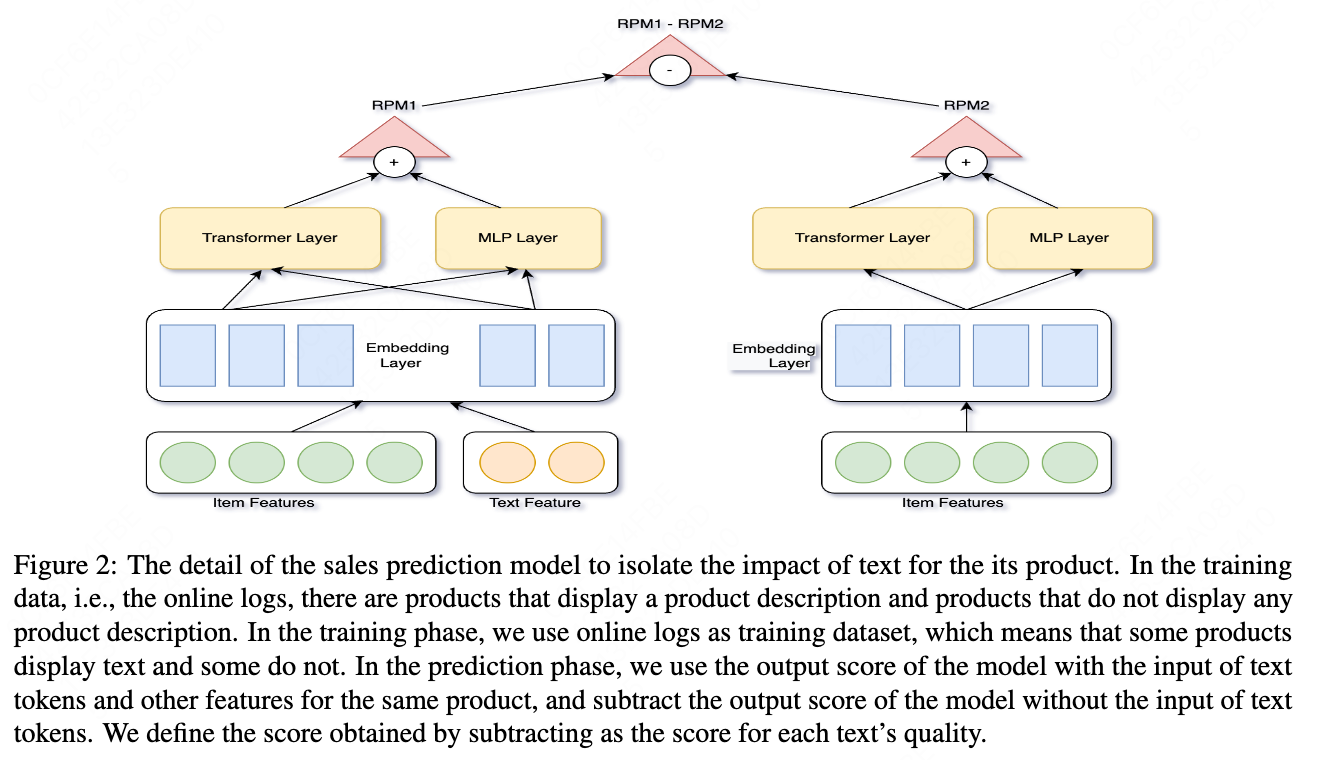
3. Experiment
3.1 Manual Evaluation
The manual evaluation is the generation available rate. The available rate is to determine whether the generated text is available for display online. We do human annotation for each data and then we compute:
\[AvailableRate = N_{good} / N_{total}\]where $N_{good}$ is the available generated text number and $N_{total}$ is the total texts that are human annotated.
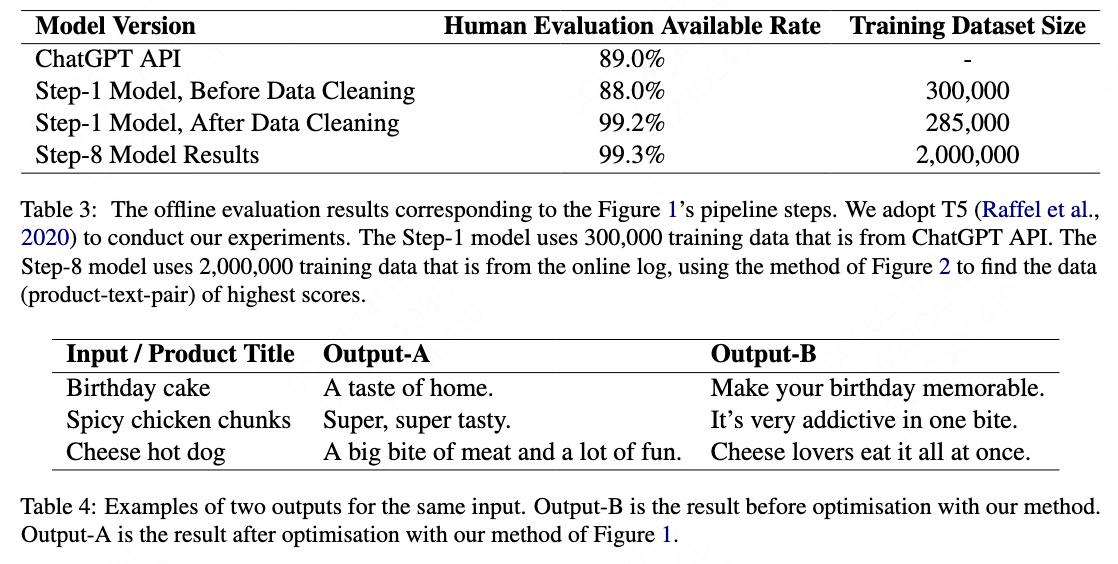
The manual comparison of the Step-1 initial results and the optimised model results. The initial model results are corresponding to the Step-1 of the Figure \cite{fig1}. The optimised model results are the generated texts from the optimised model of the Step-8 of the Figure \cite{fig1}. We find it impossible to manually determine which of the two is more appropriate to be displayed on a product.
The available rate result is shown in Table \cite{table3}. The comparison of the two generation result is shown in Table \cite{table4}.
3.2 AB Experiments
We do AB experiments to evaluate the online performance of our method. We display the two product descriptions to two groups of users. Then we count the RPM of the two groups of users. The results show that the optimised texts improve the RPM by about 0.1\%, compared to another group.
4. Discussion
In this section we illustrate the reason why we design our method. And we illustrate the baseline solution we compare.
4.1 Motivation
In order to improve the quality of the generated text, and to improve the RPM, we found that manual annotation can not achieve this, we look for supervisory signals from human behaviour of online app.
4.2 Experimental Detail
Our investigation of prompt engineering revealed minimal variation in output quality across different ChatGPT query formulations, suggesting prompt design has limited impact on final text quality for this application.
For the sales prediction model, we intentionally retained all available features without selection, as feature optimization falls outside this paper’s scope.
A critical implementation detail: When all products display descriptions, causal isolation becomes statistically infeasible. To enable rigorous analysis, we implemented a randomized control trial:
1) 50% of products displayed AI-generated descriptions
2) 50% displayed no descriptions
We tried repeating the whole pipeline of Figure \cite{fig1} to iteratively improve the results. The gain is minimal after one iteration.
4.3 Baseline Solution
We first collect the results from ChatGPT to train our T5 model. We input product title and ask ChatGPT to write product description. The problems with the ChatGPT results are that the available rate of text is 89\% and 11\% of the product description is not suitable for display. So we clean the dataset based on ChatGPT API and train the T5 model with more than 99\% available rate of generated text. We use this generated results of our T5 model as the baseline, which is the Step-1 of Figure \cite{fig1}.
We have tried putting the product attributes like product type and product tags into the prompts, combined with product title to query ChatGPT, but we do not observe some improvement of text quality and diversity by ChatGPT.
5. Related Work
5.1 Text Generation
The pre-trained model based on Transformer \cite{vaswani2017attention} has greatly improved the performance in text generation. The learning objectives include masked language modeling (MLM) and causal language modeling (CLM). MLM-based Language Models include BERT \cite{devlin2018bert}, ROBERTA \cite{liu2019roberta}. CLM-based Language Models include the GPT series works \cite{radford2018improving,radford2019language,brown2020language} and other decoder-only transformer models \cite{keskar2019ctrl}. The sequence to sequence models\cite{sutskever2014sequence} use encoder-decoder transformer \cite{vaswani2017attention} for better model flexibility. The seq2seq model is widely used in the field of text generation \cite{luong2014addressing,bahdanau2014neural}. We adopt Seq2Seq models implement our text generation tasks. The most representative models of this type include T5 \cite{raffel2020exploring} and BART \cite{lewis2020bart}. In this paper, we adopt the T5 model to conduct our experiments. We compared T5 and GPT-2\cite{radford2019language} on the same dataset and ultimately chose T5.
5.2 CTR Prediction
Sales prediction task \cite{tsoumakas2019survey,cheriyan2018intelligent} is to estimate future sales of products, which is same to the click through rate (CTR) prediction task \cite{chen2016deep,guo2017deepfm}. Sales prediction and CTR prediction both use users behaviour (click/view) as training target, which means that we collect the logs of online app to build the training dataset.
5.3 Causal Inference
The research questions that motivate most quantitative studies in the health, social and behavioral sciences are not statistical but causal in nature. Causal inference \cite{pearl2010causal,pearl2009causal} is to solve these problems. In our scenario, the product description is displayed on the product. That is, the product description, is the treatment that affects the sales of the corresponding product.
5.4 Text Quality Evaluation
The evaluation of text generation \cite{celikyilmaz2020evaluation,zhang2019bertscore} is the task that evaluate of natural language generation, for example in machine translation and caption generation, requires comparing candidate sentences to annotated references. In our scenario, however, we are unable to manually evaluate the impact of the quality of the generated product description on product sales. So we do AB experiments to count whether the generated text leads to an increase in product sales or not, to judge whether the quality of text is improved.
6. Conclusion
Improving the quality of AI-generated text for app sales is critical, as manual annotation cannot reliably assess text effectiveness. Without objective quality evaluation, optimizing text generation toward higher quality becomes unachievable. Conversely, establishing a robust evaluation method enables continuous optimization.
In this paper, we identify actionable supervisory signals within e-commerce user behavior data to iteratively enhance text quality. Our solution integrates causal inference to isolate textual impact from product-specific factors, ensuring accurate quality attribution. Experimental results demonstrate that this methodology significantly boosts app sales performance.
References
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointly
learning to align and translate. arXiv preprint
arXiv:1409.0473.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie
Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind
Neelakantan, Pranav Shyam, Girish Sastry, Amanda
Askell, et al. 2020. Language models are few-shot
learners. Advances in neural information processing
systems, 33:1877–1901.
Asli Celikyilmaz, Elizabeth Clark, and Jianfeng Gao.
2020. Evaluation of text generation: A survey. arXiv
preprint arXiv:2006.14799.
Junxuan Chen, Baigui Sun, Hao Li, Hongtao Lu, and
Xian-Sheng Hua. 2016. Deep ctr prediction in dis-
play advertising. In Proceedings of the 24th ACM
international conference on Multimedia, pages 811–
820.
Sunitha Cheriyan, Shaniba Ibrahim, Saju Mohanan, and
Susan Treesa. 2018. Intelligent sales prediction using
machine learning techniques. In 2018 International
Conference on Computing, Electronics & Communi-
cations Engineering (iCCECE), pages 53–58. IEEE.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and
Kristina Toutanova. 2018. Bert: Pre-training of deep
bidirectional transformers for language understand-
ing. arXiv preprint arXiv:1810.04805.
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li,
and Xiuqiang He. 2017. Deepfm: a factorization-
machine based neural network for ctr prediction.
arXiv preprint arXiv:1703.04247.
Nitish Shirish Keskar, Bryan McCann, Lav R Varshney,
Caiming Xiong, and Richard Socher. 2019. Ctrl: A
conditional transformer language model for control-
lable generation. arXiv preprint arXiv:1909.05858.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer Levy,
Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart:
Denoising sequence-to-sequence pre-training for nat-
ural language generation, translation, and comprehen-
sion. In Proceedings of the 58th Annual Meeting of
the Association for Computational Linguistics, pages
7871–7880.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Man-
dar Joshi, Danqi Chen, Omer Levy, Mike Lewis,
Luke Zettlemoyer, and Veselin Stoyanov. 2019.
Roberta: A robustly optimized bert pretraining ap-
proach. arXiv preprint arXiv:1907.11692.
Minh-Thang Luong, Ilya Sutskever, Quoc V Le, Oriol
Vinyals, and Wojciech Zaremba. 2014. Addressing
the rare word problem in neural machine translation.
arXiv preprint arXiv:1410.8206.
Judea Pearl. 2009. Causal inference in statistics: An
overview.
Judea Pearl. 2010. Causal inference. Causality: objec-
tives and assessment, pages 39–58.
Shrimai Prabhumoye, Alan W Black, and Rus-
lan Salakhutdinov. 2020. Exploring control-
lable text generation techniques. arXiv preprint
arXiv:2005.01822.
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya
Sutskever, et al. 2018. Improving language under-
standing by generative pre-training.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,
Dario Amodei, Ilya Sutskever, et al. 2019. Language
models are unsupervised multitask learners. OpenAI
blog, 1(8):9.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine
Lee, Sharan Narang, Michael Matena, Yanqi Zhou,
Wei Li, and Peter J Liu. 2020. Exploring the limits
of transfer learning with a unified text-to-text trans-
former. The Journal of Machine Learning Research,
21(1):5485–5551.
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014.
Sequence to sequence learning with neural networks.
Advances in neural information processing systems,
27.
Grigorios Tsoumakas. 2019. A survey of machine learn-
ing techniques for food sales prediction. Artificial
Intelligence Review, 52(1):441–447.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz
Kaiser, and Illia Polosukhin. 2017. Attention is all
you need. Advances in neural information processing
systems, 30.
Hanqing Zhang, Haolin Song, Shaoyu Li, Ming Zhou,
and Dawei Song. 2022. A survey of controllable
text generation using transformer-based pre-trained
language models. arXiv preprint arXiv:2201.05337.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q
Weinberger, and Yoav Artzi. 2019. Bertscore: Eval-
uating text generation with bert. arXiv preprint
arXiv:1904.09675.