Drop Noise For CTR Prediction
Drop Noise For CTR Prediction
Abstract
Click-through rate (CTR) prediction is task to estimate the possibility of user clicking on a recommended item. The ground truth labels of this task are the click history of users. As there are many reasons why noise data or low quality data may be generated, the training data has a certain amount of noise data or low quality data. In this work, We propose a simple but effective method to find the noise data. Our method could improve the offline AUC from 0.60 to 0.75 on our real-world test dataset of the un-drop part.
Keywords
CTR, Recommendation System, Deep Learning
1. Introduction
The prediction of click-through rate is very important in recommendation systems, and its task is to estimate the possibility of user clicking on a recommended item. In recommendation systems the goal is to maximize the CTR, so the item list for a user should be ranked by estimated CTR.
The ground truth labels of this task are the click history of users. There are many reasons that may generate noise or low quality training data. We can not clearly define what are the noise data. But our method can find the noise data that harm the performance of our model.
Previous works \cite{ref1} \cite{ref2} have shown the effectiveness of our method on human-labeled dataset. In CTR task, the training data is generated by user behavior. So if the amount of user behavior training data is large enough, we can remove the noise data and do not need to correct them.
2. Related Work
There are many works focus on the model-centric perspective of CTR task. Factorization Machines (FM) \cite{ref3} , DeepFM \cite{ref4}, Wide \& Deep model \cite{ref5} are all works that solve the model-centric perspective of this task.
Previous works \cite{ref1} \cite{ref2} focus on the data-centric perspective on human-labeled dataset and do not apply the idea to user-generated dataset like CTR task.
3. Method
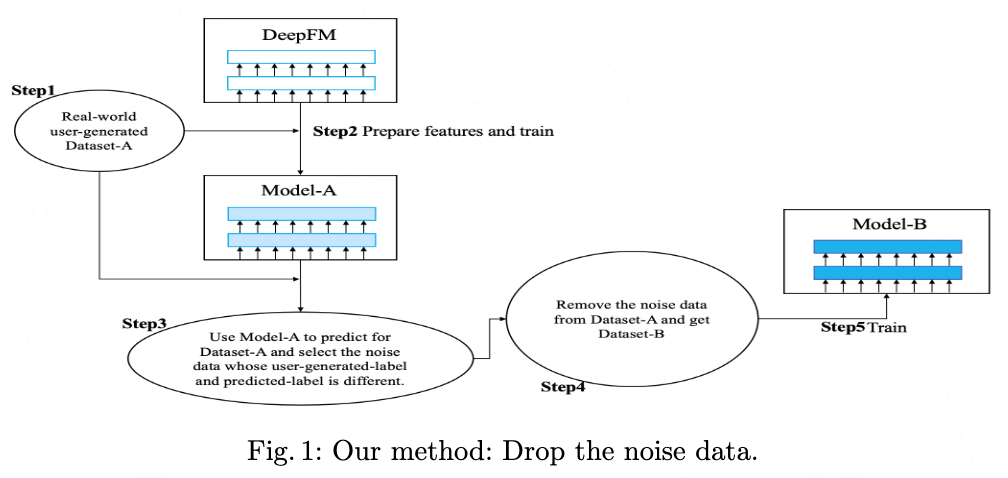
In this section, we describe our method in detail. Our method is shown in Fig 1. It includes 5 steps:
Step 1, in order to solve our industry CTR problem. We get the user-generated dataset-A and prepare features like age, gender, location.
Step 2, we train CTR deep model on dataset-A. We named the trained model of this step Model-A. Note that Model-A should not overfit the training dataset.
Step 3, we use Model-A to predict for all the dataset-A. Then we find all the data whose user-generated label and predicted-label is different. We consider they are the noise data. There are many ways to define the difference of two labels: the equality of the two labels, or the distance of the two scores.
Step 4, we remove the noise data, and we also have enough user-generated data. Then we get dataset-B.
Step 5, we train upon the dataset-B and get Model-B.
4. Experiments
In this section we describe detail of experiment parameters and list the experiment results.
4.1 Experiment Results
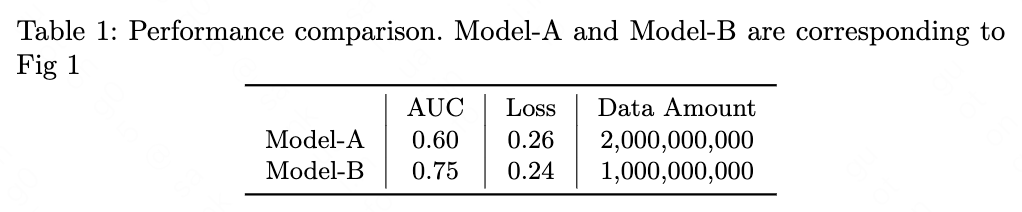
In this section, we evaluate our method on our real-world dataset. Our dataset-A contains 2,000,000,000 user-item click-or-not data and each data has 100 features. Table 1 shows the performance comparison on the dataset. The model is DeepFM. As our method is data-centric approach, we do not focus on which model we use.
5. Discussion
In subsequent observations, we found that the method proposed in this paper can effectively remove noise. However, it does not alter the dataset’s labeling rules, knowledge sources, or inherent biases.
5.1 Why dev AUC improved
Why drop-noise method work? Because deep learning is statistic-based. Take classification as example. (In a broad sense, all the machine learning tasks can be viewed as classification.)
If there are three very similar data (data-1/data-2/data-3) in total, which labels are class-A/class-A/class-B, Then the trained model will probably predict class-A for data-3.
We suppose that data-3 is wrong-labeled by human, because more people labeled these very similar data-1/data-2 to class-A.
And the trained model predict class-A for data-3. So the noise data here is data-3 by our method.
If we do not drop data-3, the model prediction for new data that is the most similar to data-3 will be class-B, which is wrong. The new data is more similar to data-3 than data-1/data-2.
If we drop data-3, the model prediction for new data that is the most similar to data-3 will be class-A, which is right.
5.2 Reason of AUC upper bound
The main reason why CTR models struggle to achieve AUC scores above 0.95 lies in the inherent unpredictability of users’ purchase intentions. Unlike well-defined NLP tasks where outcomes can be more precisely determined, user purchasing behavior itself is fundamentally uncertain - there’s no guaranteed conversion even when all predictive signals seem favorable. This essential uncertainty in decision-making creates an upper bound on model performance metrics like AUC.
5.3 Deployment for drop-noise method
In the domain of recommendation systems, it is recognized that for distinct stratified user groups — such as dividing a user group into two segments — training separate CTR models for each segment enables the application of different models to different user groups during online exposure. Consequently, the drop-noise method proposed in this paper can be implemented through user grouping. Specifically, the model refined by drop-noise will exclusively apply to the corresponding user group, while the other user group will continue to rely on the baseline model.
Alternatively, when training on combined user data from different groups, distinct corresponding weights can be assigned to the loss function. This ensures that the model appropriately accounts for the varying importance or characteristics of each user group during the optimization process.
The core reason why the drop-noise method can be deployed is that we can cluster users during the prediction phase.
But for manually labeled datasets, while we can prepare two separate models for inference based on different inputs, only the training-dataset data can be reliably used for data clustering purposes.
6. Conclusion
We apply the find-noise idea to dataset generated by user behavior and CTR task. The experiment results show our method improves the offline AUC on un-drop part of user-item data.
References
\bibitem{ref1}
Guo T. Learning From How Humans Correct[J]. arXiv preprint arXiv:2102.00225, 2021.
\bibitem{ref2}
Guo T. The Re-Label Method For Data-Centric Machine Learning[J]. arXiv preprint arXiv:2302.04391, 2023.
\bibitem{ref3}
[Rendle, 2010] Steffen Rendle. Factorization machines. In ICDM, 2010.
\bibitem{ref4}
Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
\bibitem{ref5}
Cheng H T, Koc L, Harmsen J, et al. Wide \& deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10.