Self-Refine Learning For Data-Centric Deep Learning
Self-Refine Learning For Data-Centric Deep Learning
Abstract
In industry NLP application, our manually labeled dataset has a certain number of noise data. We present a simple method to find the noise data and remove/reset them. We select the noise data whose human label is not contained in the top-K model’s predictions. The experiment result shows that our method works. For industry deep learning application, our method improve the text classification accuracy from 80.5% to 90.6% in dev dataset, and improve the human-evaluation accuracy from 83.2% to 90.1%. The conclusion is: The self-predict and remove/reset method of this paper can not improve the accuracy to more than 95% of human evaluation, without human labeling again for the training dataset.
Keywords
Deep Learning, Text Classification, NLP
1. Introduction
In recent years, deep learning \cite{ref2} and BERT-based \cite{ref1} model have shown significant improvement on almost all the NLP tasks. However, the most important factor for deep learning application performance is the data quantity and quality. We try to improve performance of the industry NLP application by correcting the noise data by other most of data.
Previous works \cite{ref11} first find the noise data which human label and model prediction is not equal and re-label the noise data manually. During the correction, the last human label and model predictions as references are viewed by the labeling people. However it need more human labeling. So in this work, we directly remove/reset the noise data whose label is not contained in the top-K (K=1,2,3…10) predictions of model.
Our key contribution is:
Based on our industry dataset, we first find the noise data which human label is not in the top-K (K=1,2,3…10) predictions of model. Then we remove/reset the noise data. The experiment results shows that our idea works for our large industry dataset.
2. Related Work
BERT \cite{ref1} is built by the multi-layer transformer encoder \cite{ref10}, which produces self-attended token representations that have been pre-trained from unlabeled text and fine-tuned for the supervised downstream tasks. BERT achieved state-of-the-art results on many sentence-level tasks on the GLUE benchmark \cite{ref3} and CLUE\cite{ref12} benchmark.
Our method is different to semi-supervised learning. Semi-supervised learning solve the problem that making best use of a large amount of unlabeled data. These works include UDA \cite{ref6}, Mixmatch \cite{ref7}, Fixmatch \cite{ref8}, Remixmatch \cite{ref9}. Our work is full supervised.
3. Our Method
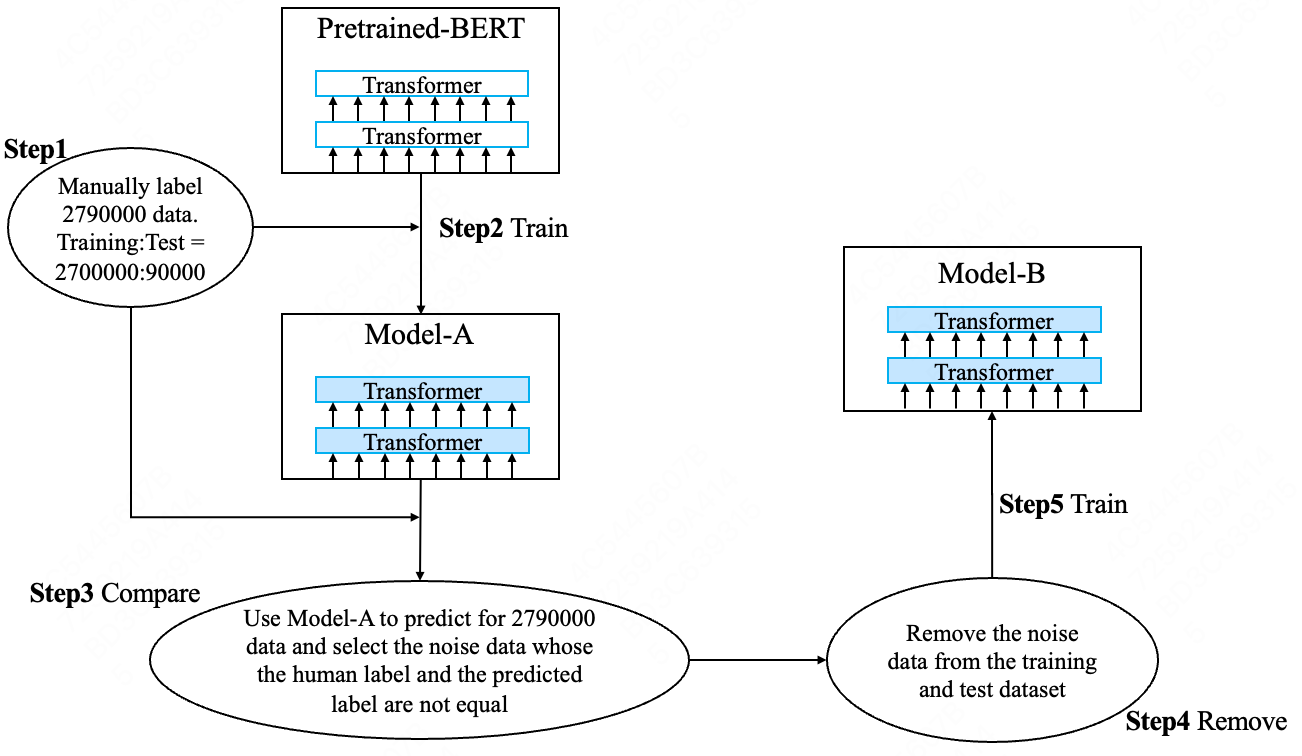 Fig 1: Remove the noise data
Fig 1: Remove the noise data
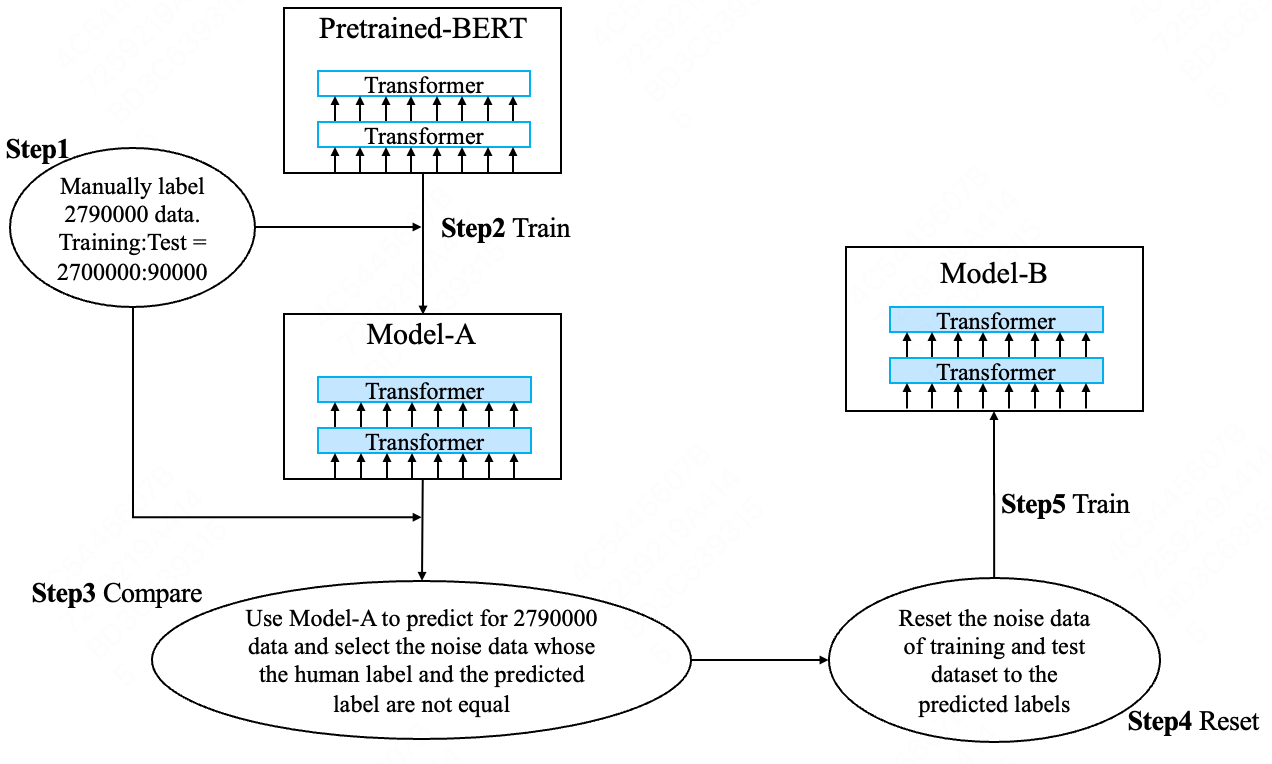 Fig 2: Reset the noise data
Fig 2: Reset the noise data
In this section, we describe our method in detail. Our methods are shown in Fig 1 and Fig 2. It includes 5 steps:
Step-1, in order to solve our industry text classification problem. We manually label 2,790,000 data and split them into 2,700,000 training data and 90,000 dev data.
Step-2, we train / fine-tune the BERT model on the 2,700,000 training data. We named the result model of this step Model-A. Note that Model-A should not overfit the training dataset.
Step-3, we use Model-A to predict for all the 2,790,000 data. Then we find all the data whose human label are not in the top-K (K=1,2,3…10) predictions of model-A. We consider they are the noise data.
Step-4, we remove/reset the noise data from the 2,700,000 and 90,000 data.
Step-5, we train and evaluate upon the dataset of step-4 and get Model-B.
4. The Model
We use BERT as our model. The training steps in our method belongs to the fine-tuning step in BERT. We follow the BERT convention to encode the input text.
5. Experiments
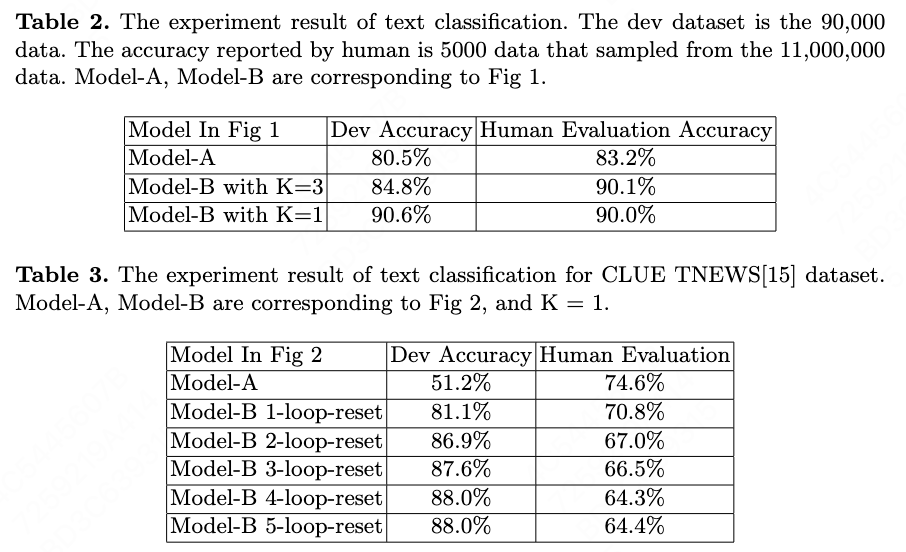
In this section we describe detail of experiment parameters and show the experiment result. The detail result is shown in Table 2. The data size in our experiment is shown in Table 1.
In fine-tuning, we use Adam \cite{ref4} with learning rate of 1e-5 and use a dropout \cite{ref5} probability of 0.1 on all layers. We use BERT-Base (12 layer, 768 hidden size) as our pre-trained model.

6. Discussion
Why removing noise method work? Because deep learning is statistic-based. Take classification as example. (In a broad sense, all the machine learning tasks can be viewed as classification.)
If there are three very similar data (data-1/data-2/data-3) in total, which labels are class-A/class-A/class-B, Then the trained model will probably predict class-A for data-3.
We suppose that data-3 is wrong-labeled by human, because more people labeled these very similar data-1/data-2 to class-A.
And the trained model predict class-A for data-3. So the noise data here is data-3 by our method.
If we do not remove data-3, the model prediction for new data that is the most similar to data-3 will be class-B, which is wrong. The new data is more similar to data-3 than data-1/data-2.
If we remove data-3, the model prediction for new data that is the most similar to data-3 will be class-A, which is right.
6.1 ChatGPT
In ChatGPT \cite{ref14}, OpenAI use human-labeled policy-prediction-data as reward to train text-generation transformer \cite{ref10} policy-model. In fact, if we collected the good/bad feedbacks/rewards from users, we can remove the bad feedback data for text-generation policy-model, and only use good feedback data to merge into the policy dataset, which means we do not need the text-match-based reward-model.
7. Conclusion
Identifying and removing noisy data from the training dataset via self-prediction is ineffective. To genuinely improve data quality, it is essential to correct the noisy data \cite{ref13} rather than just removing it.
References
\bibitem{ref1}
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
\bibitem{ref2}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref3}
Wang A, Singh A, Michael J, et al. GLUE: A multi-task benchmark and analysis platform for natural language understanding[J]. arXiv preprint arXiv:1804.07461, 2018.
\bibitem{ref4}
Kingma D P, Ba J. Adam: A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
\bibitem{ref5}
Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. The journal of machine learning research, 2014, 15(1): 1929-1958.
\bibitem{ref6}
Xie Q, Dai Z, Hovy E, et al. Unsupervised data augmentation for consistency training[J]. arXiv preprint arXiv:1904.12848, 2019.
\bibitem{ref7}
Berthelot D, Carlini N, Goodfellow I, et al. Mixmatch: A holistic approach to semi-supervised learning[J]. arXiv preprint arXiv:1905.02249, 2019.
\bibitem{ref8}
Sohn K, Berthelot D, Li C L, et al. Fixmatch: Simplifying semi-supervised learning with consistency and confidence[J]. arXiv preprint arXiv:2001.07685, 2020.
\bibitem{ref9}
Berthelot D, Carlini N, Cubuk E D, et al. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring[J]. arXiv preprint arXiv:1911.09785, 2019.
\bibitem{ref10}
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
\bibitem{ref11}
Guo T. Learning From How Humans Correct[J]. arXiv preprint arXiv:2102.00225, 2021.
\bibitem{ref12}
Xu, Liang, et al. "Clue: A chinese language understanding evaluation benchmark." arXiv preprint arXiv:2004.05986 (2020).
\bibitem{ref13}
Guo T. The Re-Label Method For Data-Centric Machine Learning[J]. arXiv preprint arXiv:2302.04391, 2023.
\bibitem{ref14}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
\bibitem{ref15}
Xu L, Hu H, Zhang X, et al. CLUE: A Chinese language understanding evaluation benchmark[J]. arXiv preprint arXiv:2004.05986, 2020.