A Unified Framework for NLP Tasks by ReLabel Method
A Unified Framework for NLP Tasks by ReLabel Method
Abstract
In industry deep learning application, our dataset has a certain number of noisy data. The init datasets are from human labeling or LLM (large language model) generation or user behavior log. To solve this problem and achieve more than 90 score in dev dataset, we present a framework to find the noisy data and relabel the noisy data, given the model predictions as references in relabeling. The process of relabeling can be done manually or using LLM for annotation. In this paper, we illustrate our idea for a broad set of deep learning tasks, includes classification, sequence tagging, object detection, sequence generation, click-through rate prediction. The dev dataset evaluation results and human evaluation results verify our idea.
Keywords
NLP, LLM
1. Introduction
In recent years, deep learning \cite{ref1} and LLM \cite{ref2,ref3,ref4,ref5,ref7,ref8,ref9,ref10} have shown significant improvement on natural language processing(NLP), computer vision and speech processing technologies. However, the model performance is limited by the dataset quality. The main reason is that the dataset has a certain number of noisy data. In this paper, we present a framework to find the noisy data and relabel the noisy data for NLP tasks. In this paper, ‘NLP’ refers to a specific NLP task, such as NER, text classification, specific text generation, etc.. Specifically, we define ‘NLP tasks’ as those that can be solved by the ‘data-cover’ paradigm. ‘LLM tasks’, on the other hand, refer to the paradigm that relies on trillion-token pre-training and million-token post-training data. Our idea can apply to a broad set of deep learning industry applications.
This paper’s contribution lies in the demonstration that the quality of a training dataset can be enhanced by first generating it with LLM and subsequently using LLM for re-annotation, without the need for manual re-annotation. Due to the inherent instability of LLM-based annotation, the method proposed in this paper also becomes a necessity.
2. Method
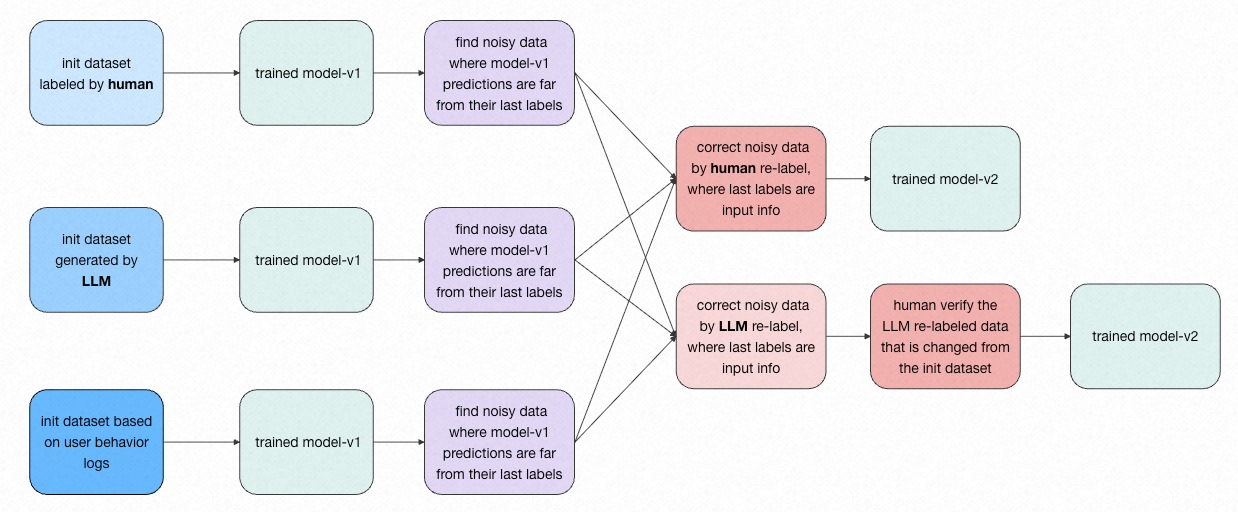


2.1 Initial Datasets
Our initial datasets can be sourced from the following three methods:
1) Manual Annotation: Data noise in a manually annotated dataset, using a classification task as an example, occurs when there is disagreement among annotators. For instance, for 3 very similar data to-label, 2 annotators assign label-A, while 1 annotator assigns label-B.
2) LLM Generation: For datasets generated by LLM, data noise in a classification task often stems from overlapping or repetitive definitions for labels within the prompts. When using an LLM to label an initial training dataset, you can evaluate the quality of the current prompt by measuring its accuracy on the dev dataset, which is split from the overall dataset. The dev accuracy serves as a proxy for the amount of ambiguous data generated by the prompt; a high accuracy on the dev dataset indicates that the resulting training data has low ambiguity. Before generating an initial training dataset using an LLM, it is crucial to first prepare a human-annotated, real-world test dataset. This test dataset should then be used to debug and refine the prompts, ensuring they are fully optimized to maximize the overall quality of the LLM’s annotations.
3) User Behavior Logs: Datasets based on user behavior logs are constructed from user actions. For example, in an e-commerce scenario, a dataset can be built based on whether a user clicks on an item or places an order.
2.2 Find Noisy Data And Relabel
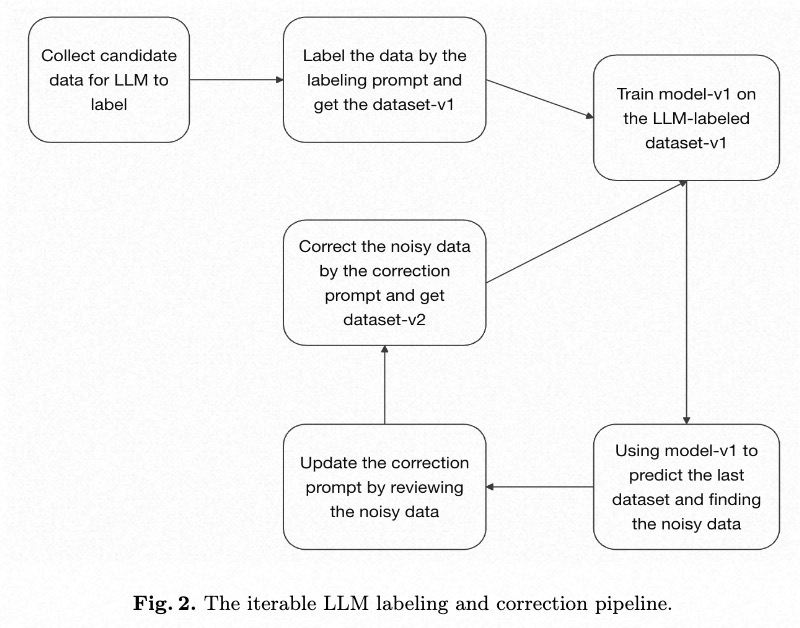
We first train a model on the initial dataset. Specifically, we choose the model from the point where the dev loss no longer decreases, using it as our model for self-prediction. Therefore, we use this model to generate predictions for the entire training and dev dataset. The data where the model’s prediction differs from the original ground-truth label, or where the prediction error is large, are identified as potential noise/badcases. This method allows us to find approximately 2-10% of the dataset for re-annotation. This approach not only reduces manual annotation costs, but its effectiveness in identifying noisy data has also been validated by our experimental results.
We perform a manual re-annotation of the noisy data. During this process, we provide the human annotators with both the original label and the model’s prediction as input information. In the era of LLM, we are now replacing this manual re-annotation with an automated process using an LLM. Similarly, we feed the LLM the same inputs: the original label and the model’s prediction. In detail, we ask the LLM within the prompt to correct noisy data made in the last round of labeling. We require the LLM’s error correction output to be chosen from either the result of our trained model or the result from the previous annotation \cite{ref6}. For example, in a 10-class text classification task, the correction step for the LLM is simplified to a 2-class classification problem, where the candidates are just 2 labels: the previously annotation and the one predicted by the trained model. To be specific, in the prompt we use for LLM annotation during the correction step, we only provide the definitions and examples for the candidate labels, and do not include the definitions and examples for the other labels in the prompt.
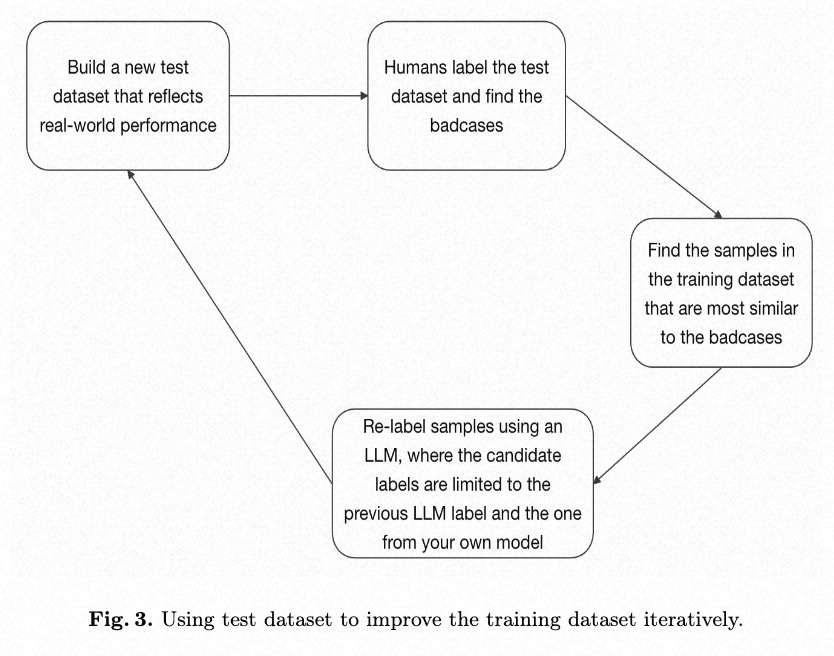
2.3 Find Badcases And Relabel
Once we achieved over 93% dev accuracy using self-predict and LLM re-labeling, we need to build a test dataset reflecting real-world performance. This requires manual annotation by a human-in-the-loop. Next, we identify badcases in the test dataset where our model’s predictions disagree with the human labels. We use these badcases to find the most similar samples in the training dataset. These found samples are then re-labeled by an LLM. During the LLM relabeling process, we instruct the LLM via the prompt to treat the human-annotated label from the test dataset and the last label as the candidate labels.
We do still need to manually annotate the test dataset. However, the dataset is small in size, and more importantly, this is the only step in our entire workflow that requires human annotation. This test dataset is crucial as it allows us to definitively determine our model’s performance by providing a benchmark that reflects real-world performance.
3. Experimental Results
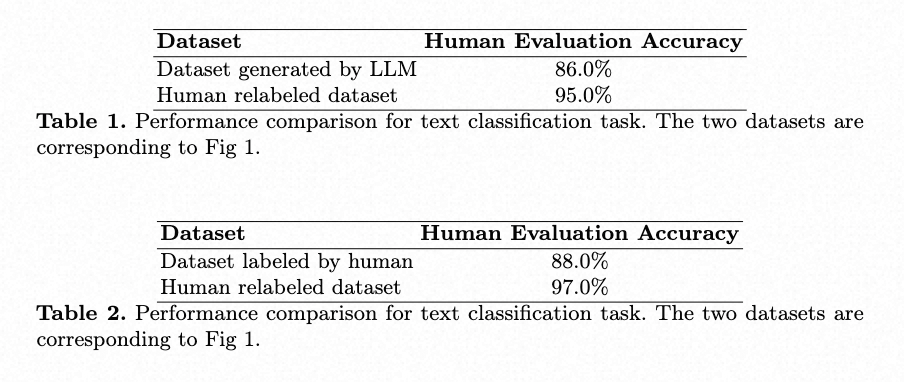

4. Discussion
We find noisy data by contrasting original labels with model predictions. To correct noisy labels, LLM can be employed to relabel data, thereby reducing the scope of manual annotation. In the LLM relabeling step, both the predicted labels and scores from our trained NLP model can be fed to the LLM as the information needed for noise correction.
The key advantage of prompt-based data annotation is its efficiency in batch processing. By including a few examples (few-shot learning) in the prompt for a LLM, the LLM can generalize and apply the annotation logic to an entire batch of data. Therefore, LLMs bring the amount of data labeling down to a quantity that is manageable for a single developer. For the relabeling step, the prompt-based LLM can be seen as a batch annotation/correction tool. Humans write few-shot examples into the prompts to correct noise in the training dataset. Although LLMs are considered a tool for batch annotation, we’ve found in practice that providing a large number of showcases (examples) is not very effective. By examining the LLM’s reasoning process, we observed that it can utilize a maximum of 1-5 showcases, even when we provide 20-30. Unlike humans, an LLM cannot automatically induce the underlying rules from a large set of showcases and then perform annotation. Consequently, batch-fixing specific badcases must be achieved through other methods of prompt optimization.
Furthermore, any incorrect labels (bad cases) generated by the LLM can be identified through manual review and then fed back into the prompt as new examples. This iterative optimization of the prompt allows for the batch correction of similar errors throughout the dataset. Specifically, taking text classification as an example, our correction process is iterative. In each cycle, we sample and review bad cases from the latest training dataset, correct them, and then append them as new examples to the LLM annotation prompt. Crucially, we do not use the updated prompt to re-label the entire training dataset, given the inherent instability of LLM annotations. This is precisely what necessitates the bad case discovery method described in this paper.
The LLM-relabel method can also be applied to the post-training of LLMs. In this process, after identifying noisy data within the post-training dataset, we use the LLM to correct it.
Humans also have a re-label mechanism, through which they grow and iterate. For example, when writing a prompt for an LLM, a person might review and modify the prompt after seeing the result of the LLM. For another example, when humans solve problems, they correct their own understanding by reviewing the solutions after completing a task.
5. Conclusion
In the era of LLM, our goal is to train models for NLP tasks. To correct the noise in our initial dataset, we propose a framework that supports both a human-in-the-loop (HITL) and an LLM-in-the-loop (LITL) approach. Experimental results have validated the effectiveness of our method. Our idea can apply to a broad set of deep learning industry applications.
The core of improving the accuracy of an NLP task ultimately comes down to two points: first, how to find ambiguous data and badcases, and second, how to efficiently fix them in batches. We have verified that our method of correcting ambiguous data is highly effective for improving accuracy on the dev dataset. As for improving the test dataset accuracy, our approach is equivalent to iteratively correcting badcases in batches. Once an improvement in test dataset accuracy is achieved, we then need to annotate a new test dataset.
Our ultimate goal is to automatically ensure all data is right and to achieve a 100% accurate training dataset for any specific task without human labeling.
Reference
\bibitem{ref1}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref2}
Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
\bibitem{ref3}
Radford A. Improving language understanding by generative pre-training[J]. 2018.
\bibitem{ref4}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
\bibitem{ref5}
Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
\bibitem{ref6}
Tong Guo. Automatic Label Error Correction. TechRxiv. March 12, 2025.
\bibitem{ref7}
Yang A, Li A, Yang B, et al. Qwen3 technical report[J]. arXiv preprint arXiv:2505.09388, 2025.
\bibitem{ref8}
Liu A, Feng B, Xue B, et al. Deepseek-v3 technical report[J]. arXiv preprint arXiv:2412.19437, 2024.
\bibitem{ref9}
Guo D, Yang D, Zhang H, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning[J]. Nature, 2025, 645(8081): 633-638.
\bibitem{ref10}
Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models[J]. arXiv preprint arXiv:2402.03300, 2024.