The Re-Label Method For Data-Centric Machine Learning
The Re-Label Method For Data-Centric Machine Learning
Abstract
In industry deep learning application, our manually labeled dataset has a certain number of noisy data. To solve this problem and achieve more than 90 score in dev dataset, we present a simple method to find the noisy data and re-label the noisy data by human, given the model predictions as references in human labeling. In this paper, we illustrate our idea for a broad set of deep learning tasks, includes classification, sequence tagging, object detection, sequence generation, click-through rate prediction. The dev dataset evaluation results and human evaluation results verify our idea.
Keywords
Deep Learning, Human Labeling, Data Centric, Text-to-Speech, Speech-to-Text, Text Classification, Image Classification, Sequence Tagging, Object Detection, Sequence Generation
1. Introduction
In recent years, deep learning \cite{ref1} model have shown significant improvement on natural language processing(NLP), computer vision and speech processing technologies. However, the model performance is limited by the human labeled data quality. The main reason is that the human labeled data has a certain number of noisy data. Previous work \cite{ref2} has propose the simple idea to find the noisy data and correct the noisy data. In this paper, we first review the way we achieve more than 90 score in classification task, then we further illustrate our idea for sequence tagging, object detection, sequence generation, click-through rate (CTR) prediction.
2. Background
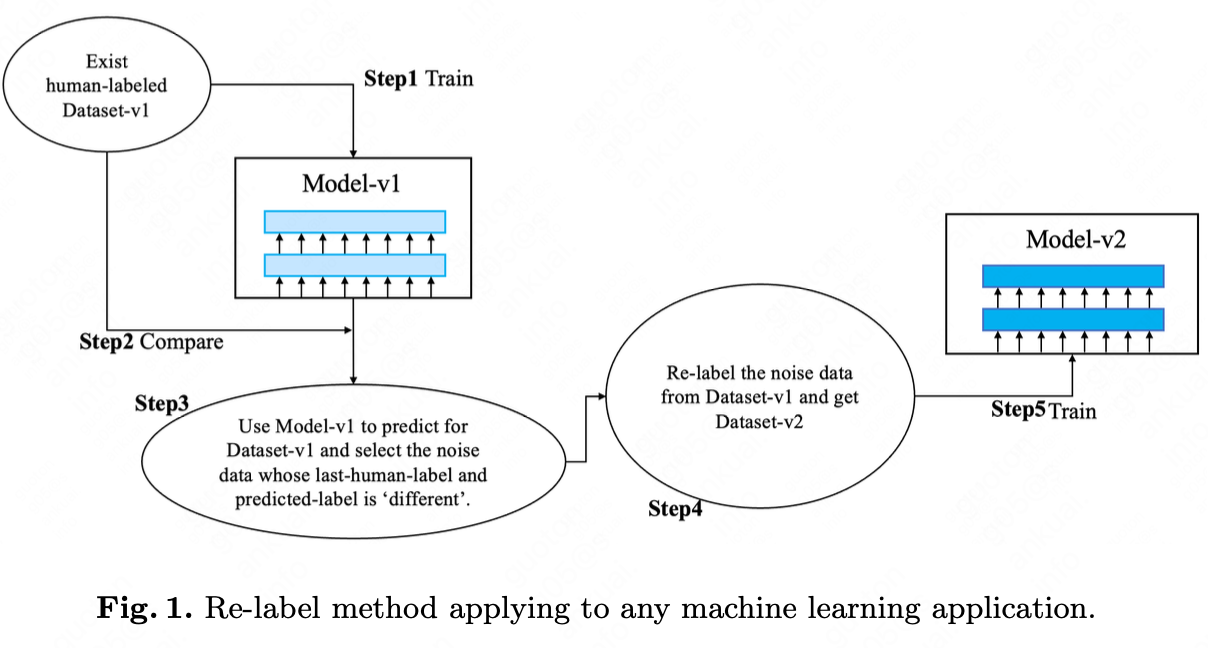
In previous work \cite{ref2}, we illustrate our idea in these steps:
-
It is a text classification task. We have a human labeled dataset-v1.
-
We train a BERT-based \cite{ref3} deep model upon dataset-v1 and get model-v1.
-
Using model-v1 to predict the classification labels for dataset-v1.
-
If the predicted labels of dataset-v1 do not equal to the human labels of dataset-v1, we think they are the noisy data.
-
We label the noisy data again by human, while given the labels of model and last label by human as reference. Then we get dataset-v2 and model-v2.
-
We loop these re-label noisy data steps and get the final dataset and final model.
3. Same Idea and More Applications
3.1 sequence tagging
We take named entity recognition(NER) as example for the sequence tagging like tasks. In NER task, we extract several classes of key phrase from a sentence. Follow our idea, we view each class of NER task as a classification task. Then our steps are:
-
It is a NER task. We have a human labeled dataset-v1.
-
We train a BERT-based \cite{ref3} deep model upon dataset-v1 and get model-v1.
-
Using model-v1 to predict the sequence labels of one class for dataset-v1.
-
If the predicted labels of dataset-v1 do not equal to the human labels of dataset-v1, we think they are the noisy data.
-
We label the noisy data again by human, while given the labels of model and last label by human as reference. Then we get dataset-v2. In actual operation, if the labeling peoples are sufficient, we label the NER results. If the labeling peoples are not sufficient, the labeling task can be a choice question for labeling peoples. Then we get dataset-v2 and model-v2.
-
We loop these re-label noisy data steps for all the classes of NER and get the final dataset and final model.
3.2 object detection
Object detection is a computer vision technique that allows us to identify and locate objects in an image or video. Follow our idea, we view each kind of bounding box as a classification task. Then our steps are:
-
It is a object detection task. We have a human labeled dataset-v1.
-
We train a Swin Transformer\cite{ref4} upon dataset-v1 and get model-v1.
-
Using model-v1 to predict the bounding boxes of one class for dataset-v1.
-
If the predicted bounding box of dataset-v1 is far from the human labeled bounding box of dataset-v1, we think they are the noisy data.
-
We label the noisy data again by human, while given the bounding boxes of model and last label by human as reference. Then we get dataset-v2 and model-v2.
-
We loop these re-label noisy data steps for all the classes of object detection and get the final dataset and final model.
3.3 sequence generation
The key step of our idea is about how to judge the noisy data. For sequence generation, we can use edit distance score or other sequence similarity evaluation method. Then our steps are:
-
We take text generation task as example. We have an origin labeled dataset-v1. The data has input sentence and output sentence.
-
We train a Encoder-Decoder Transformer\cite{ref5} upon dataset-v1 and get model-v1.
-
Using model-v1 to predict the generated sentences for dataset-v1’s input sentences.
-
If the distance score of model-generated sentences is far from the origin output sentences of dataset-v1, we think they are the noisy data. In actual operation, if the model result and the origin output sentence does not have common token, we think the data is a noisy data.
-
We label the noisy data again by human, while given the generated sentences of model and origin output sentence as reference. In actual operation, it can be a choice question for labeling people. The labeling people chooses the best result from model results and origin output sentence. Then we get dataset-v2 and model-v2.
-
We loop these re-label noisy data steps and get the final dataset and final model.
3.4 click-through rate prediction
For CTR task, we use the methods of \cite{ref6} that drop the the noisy data. CTR task is a click-or-not prediction task, we choose a threshold between the predicted score and the 0/1 online label score to judge whether the data is the noisy data. In this way, we could improve the AUC in dev dataset but the online performance should test online.
4. Experimental Results
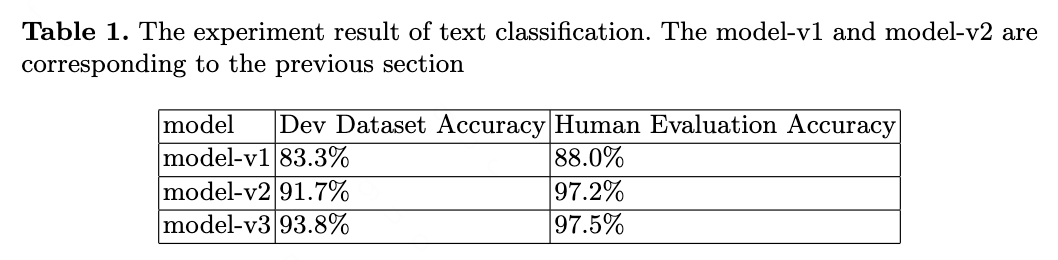
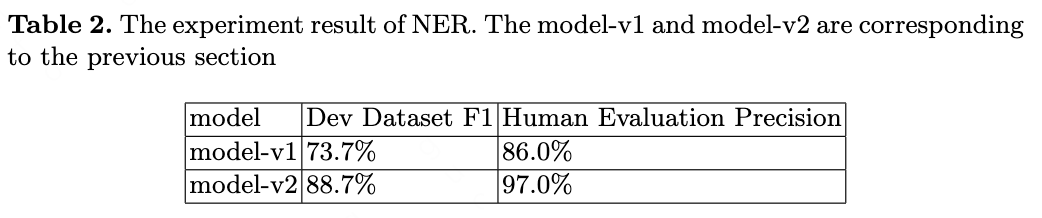
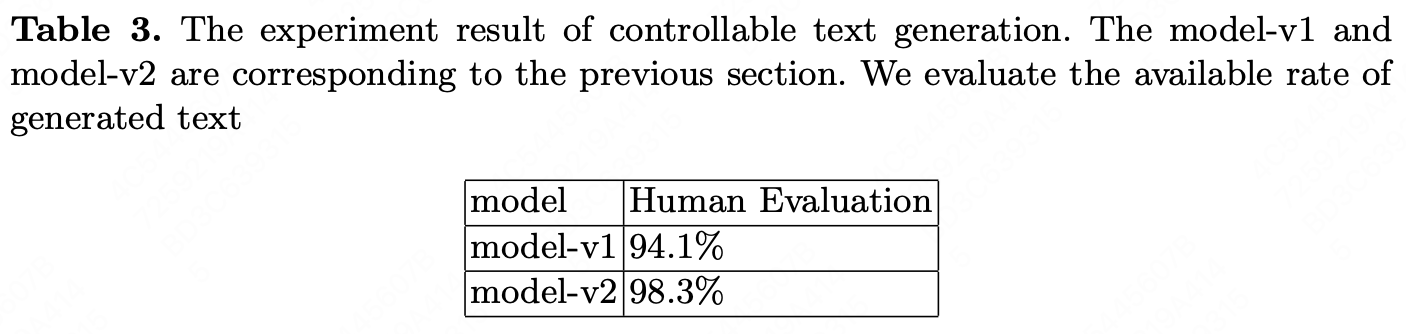
We do the experiments of text classification, NER, text generation to verify our idea. The results is shown in Table 1, Table 2, Table 3. We also do a lot of other classification task and NER task of other dataset. The improvement is also significant and we do not list the detail results.
5. Discussion
Why re-label method work? Because deep learning is statistic-based. Take classification as example. (In a broad sense, all the machine learning tasks can be viewed as classification.) If there are three very similar data (data-1/data-2/data-3) in total, which labels are class-A/class-A/class-B. Then the trained model will probably predict class-A for data-3. We assume that data-3 is wrong labeled to class-B by human, because more people label its similar data to class-A. If we do not correct data-3, the model prediction for new data that is the most similar to data-3 will be class-B, which is wrong. The new data is more similar to data-3 than data-1/data-2.
The improvement reason is also based on the better and better understanding for the specific task’s labeling rule/knowledge of labeling human once by once. Human-in-the-loop here means that in each loop the labeling human leader should learn and summarize the corrected rule/knowledge based on the last loop.
In the labeling details, the to-label dataset can be sorted for people to read and label, in order for better labeling efficiency. Also, sorted dataset can benefit the discriminating for similar data.
The cost of annotation time is crucial for deep learning tasks based on manually labeled data. If there is not enough labeling manpower, we must find ways to reduce the amount of data that needs to be labeled. If we can reduce the amount of data to be labeled to a level that a single programmer can handle, then we do not need an additional labeling team.
6. Related Work
6.1 Pseudo-label-based methods
The work\cite{ref7} proposes pseudo-label-based method to improve data quality without human re-label, which is different from our method. Our method is to improve the data quality for model of 97% accuracy/precision/recall/BLEU/AUC by human re-label.
The work\cite{ref8} proposes label-guess-based method to improve data quality without human re-label, which is different from our method. Our method get the guess-label as reference for human re-label.
6.2 ChatGPT
The work\cite{ref9} of OpenAI also use model predictions for human as references to label. The work\cite{ref9} use the new human-labeled data from model predictions to train the reward model, which is named as reinforcement learning from human feedback(RLHF).
Our work do not have the reward model of RLHF, the differnce between RLHF and our re-label method is that RLHF focus on using the model predictions as training dataset of reward model, and our re-label method focus on correcting the origin training dataset of policy model. Also in RLHF, the new human-labeled data from model predictions do not conflict to our method, because the new data can be simply merged to the whole dataset of policy model, and then to re-label/re-correct by our method.
Also, the correction for policy by the reward model of RLHF is same to correct all the related data/labels that found by the patterns or substrings of the badcases. The detail pattern-based human-correct method is illustrated at \cite{ref10}.
6.3 Other Works
For object detection task, \cite{ref11} uses the re-label method and surpasses human performance in offline LiDAR based 3D object detection.
7. Conclusion
We argue that the key point to improve the industry deep learning application performance is to correct the noisy data. We propose a simple method to achieve our idea and show the experimental results to verify our idea.
For future optimization directions, we believe that expanding the ‘coverage’ of the dataset on the basis of achieving 100% accuracy on the training dataset can lead to better deep learning models.
References
\bibitem{ref1}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref2}
Guo T. Learning From How Humans Correct[J]. arXiv preprint arXiv:2102.00225, 2021.
\bibitem{ref3}
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
\bibitem{ref4}
Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[J]. arXiv preprint arXiv:2103.14030, 2021.
\bibitem{ref5}
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
\bibitem{ref6}
Guo, Tong (2021): Self-Refine Learning For Data-Centric Deep Learning. TechRxiv. Preprint. https://doi.org/10.36227/techrxiv.16610629.v8
\bibitem{ref7}
Yun S, Oh S J, Heo B, et al. Re-labeling imagenet: from single to multi-labels, from global to localized labels[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 2340-2350.
\bibitem{ref8}
Nicholson B, Zhang J, Sheng V S, et al. Label noise correction methods[C]//2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA). IEEE, 2015: 1-9.
\bibitem{ref9}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
\bibitem{ref10}
Guo, Tong (2022): Re-Label By Data Pattern For Knowledge Driven Deep Learning. TechRxiv. Preprint. https://doi.org/10.36227/techrxiv.20485917.v6
\bibitem{ref11}
Fan L, Yang Y, Mao Y, et al. Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object Detection[J]. arXiv preprint arXiv:2304.12315, 2023.