Learning From How Humans Correct
Learning From How Humans Correct
Abstract
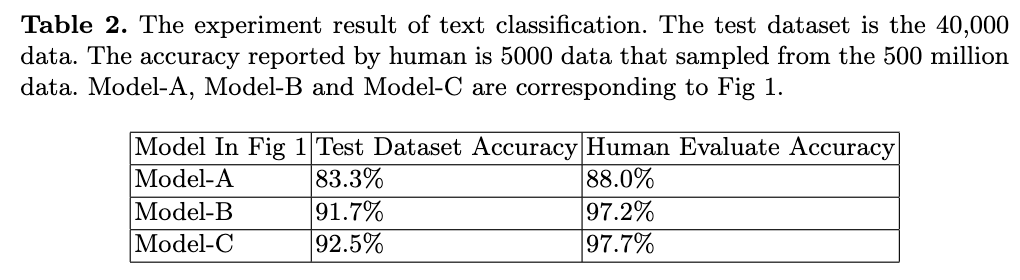
In industry NLP application, our manually labeled dataset has a certain number of noisy data. We present a simple method to find the noisy data and relabel them manually, meanwhile we collect the correction information. Then we present novel method to incorporate the human correction information into deep learning model. Human know how to correct noisy data. So the correction information can be inject into deep learning model. We do the experiment on our own text classification dataset, which is manually labeled, because we need to relabel the noisy data in our dataset for our industry application. The experiment result shows that our learn-on-correction method improve the classification accuracy from 91.7% to 92.5% in test dataset. The 91.7% accuracy is trained on the corrected dataset, which improve the baseline from 83.3% to 91.7% in test dataset. The accuracy under human evaluation achieves more than 97%.
Keywords
Deep Learning, Text Classification, NLP, Human Labeling, Data Centric
1. Introduction
In recent years, deep learning \cite{ref2} and BERT-based \cite{ref1} model have shown significant improvement on almost all the NLP tasks. However, past methods did not inject human correction information into the deep learning model. Human interact with the environment and learn from the feedback from environment to correct the their own error or mistake. Our method try to solve the problem that let deep learning model imitate how human correct.
In order to solve the problem we present a learning framework. The framework mainly works for our industry application dataset, because the problem starts from our industry application. In order to solve the text classification problem in our industry application, we first label a dataset. Then we can find the noisy data in the dataset and relabel them. The relabeling step collects the human correction information.
To the best of our knowledge, this is the first study exploring the improvement of injecting human correction information into deep model for natural language understanding. Our key contribution are 3 folds:
-
Based on our dataset, we first present the simple step to find the noisy data and relabel the noisy data.
-
We present the method to inject the human correction information into BERT for text classification.
-
Our learning framework can apply to a broad set of deep learning industry applications whose dataset is manually labeled.
2. Related Work
BERT \cite{ref1} is constructed by the multi-layer transformer encoder \cite{ref10}, which produces contextual token representations that have been pre-trained from unlabeled text and fine-tuned for the supervised downstream tasks. BERT achieved state-of-the-art results on many sentence-level tasks from the GLUE benchmark \cite{ref3}. There are two steps in BERT’s framework: pre-training and fine-tuning. During pre-training, the model is trained on unlabeled data by using masked language model task and next sentence prediction task. Apart from output layers, the same architectures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initialize models for different down-stream tasks.
Our method is different to semi-supervised learning. Semi-supervised learning solve the problem that making best use of a large amount of unlabeled data. These works include UDA \cite{ref6}, Mixmatch \cite{ref7}, Fixmatch \cite{ref8}, Remixmatch \cite{ref9}. These works do not have the human correction information. Our work has a clear goal that is to learn how humans correct their mistake. \cite{ref11} studies the PN learning problem of binary classification. But our idea can apply to a broad set of deep learning industry applications.
The work\cite{ref12} of OpenAI also use model predictions for human as references to label. The work\cite{ref12} use the new human-labeled data from model predictions to train the reward model, which is reinforcement learning from human feedback(RLHF). Our work does not have the reward model of RLHF, the differnce between RLHF and our relabel method is that RLHF focuses on using the reward-model/reward-dataset to guide policy-model/policy-dataset, and our relabel method focus on correcting the policy dataset. Also, the new human-labeled data for reward-model does not conflict to our method, because the new human-feedback reward dataset can be simply merged to the policy dataset, and then to relabel/correct by our method.
Also, correcting the \cite{ref12}’s policy by reward model is same to correcting all the related data/labels in policy training dataset. And the detail pattern-based/substring-based human-correct method is illustrated at \cite{ref13}. \cite{ref13} uses the human-feedback data to correct the policy training dataset. In summary, our method focuses on getting a high quality policy dataset.
Confident learning (CL) \cite{ref14} developed a novel approach to estimate the joint distribution of label noise and explicated theoretical and experimental insights into the benefits of doing so. CL demonstrated accurate uncertainty quantification in high noise and and sparsity regimes, across multiple datasets, data modalities, and model architectures. CL is a data-centric \cite{ref15} approach which focuses instead on label quality by characterizing and identifying label errors in datasets, based on the principles of pruning noisy data, counting with probabilistic thresholds to estimate noise, and ranking examples to train with confidence. But our method is more practical and simple.
3. Our Method
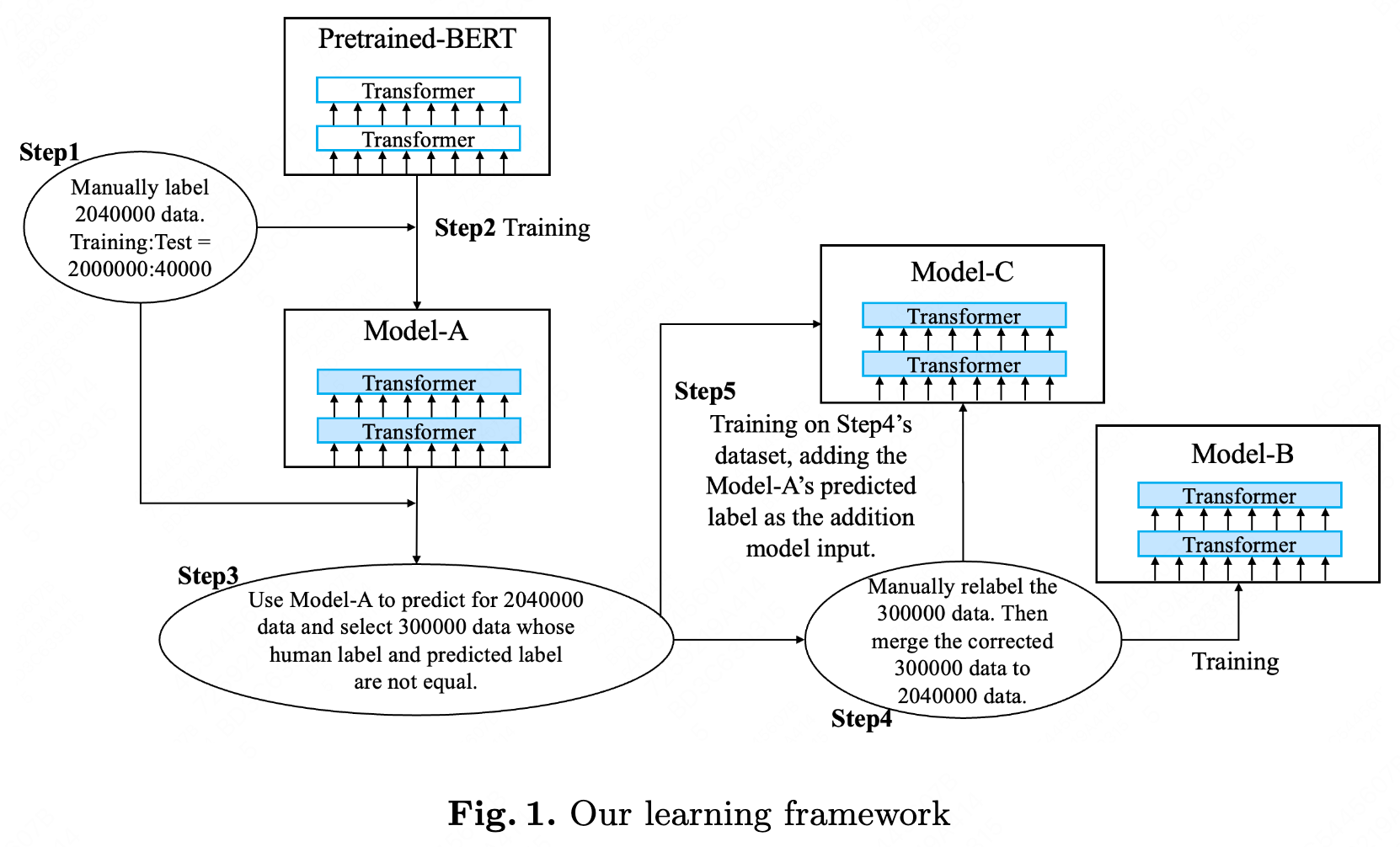
In this section, we describe our method in detail. Our learning framework is shown in Fig 1. The framework includes 5 steps:
Step 1, in order to solve the industry text classification problem. We label 2,040,000 data and split them into 2,000,000 training data and 40,000 test data. The 2,040,000 data are sampled from our application database whose data size is 500 million.
Step 2, we train / fine-tune the BERT model on the 2,000,000 training data. We named the result model of this step Model-A. Note that Model-A should not overfit the training dataset.
Step 3, we use Model-A to predict for all the 2,040,000 data. Then we find 300,000 data whose predicted label and human label are not equal. We consider it is the noisy data. In detail, there are 294,120 noisy data in the training dataset and 5,880 noisy data in the test dataset.
Step 4, we manually relabel 300,000 data and merge back to the 2,040,000 data. Then we get the merged 2,040,000 data. During the relabeling, the last label by human and the model-A’s predicted label are listed as the references for people. But labeling people also make their own decision.
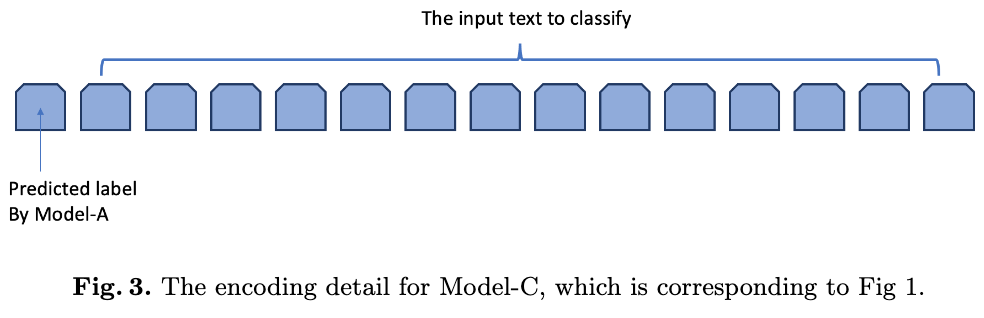
Step 5, we add the Model-A’s predicted one-hot label as the addition input for training / fine-tuning a new model. The detail encoding method for the predicted label is described in the next section. We named the result model of this step Model-C. The Model-A’s predicted one-hot labels represent the before-corrected information. The training ground truth for Model-C contains the 294,120 corrected human label, which represent the corrected information. So Model-C is learning how to correct and learning the text classification task in the same time.
4. The Model
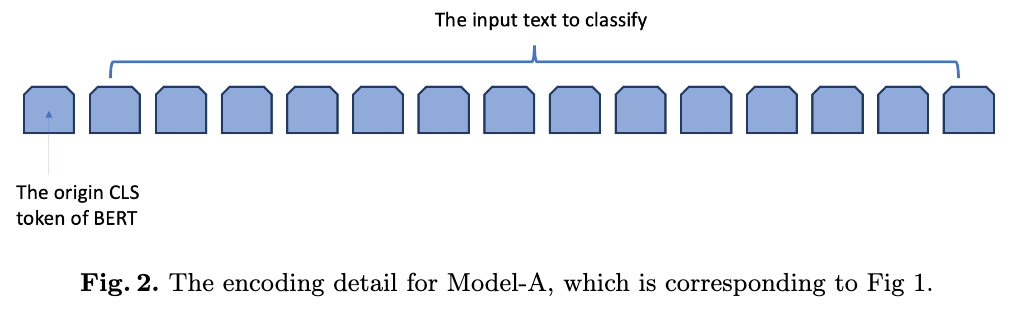
We use BERT as our model. The training steps in our method belongs to the fine-tuning step in BERT. We follow the BERT convention to encode the input text. The encoding detail for Model-A is shown in Fig 2. The encoding detail for Model-C is shown in Fig 3.
5. Experiments
In this section we describe detail of experiment parameters and show the experiment result. The detail result is shown in Table 2. The data size in our experiment is shown in Table 1.
In fine-tuning, we use Adam \cite{ref4} with learning rate of 1e-5 and use a dropout \cite{ref5} probability of 0.1 on all layers. We use BERT-Base (12 layer, 768 hidden size) as our pre-trained model.

6. Discussion
In step 4 of Fig 1, the manually relabeling can correct the noisy 300,000 data. Because the selected 300,000 data is unfitting to the Model-A, the relabeling’s ‘worst’ result is the origin last human’s label.
The step 5 in Fig 1 is the core contribution of our work. In step 5, the predicted label of Model-A contains the before-human-corrected information. The ground truth for Model-C contains the after-human-corrected information. So the model is learning the human correction.
We could use the before-corrected human label (i.e., the ground truth in step 1 of Fig 1) as the input for Model-C. But this way can not apply to real industry inference. Because we can not get the before-corrected human label as the input of Model-C in real industry application. In real industry application, we use the Model-A to predict one-hot label as input for Model-C.
Human evaluation accuracy is higher than the test dataset accuracy, because we randomly sampled 5000 data from the 500 million data. The sampled 5000 data represents the great majority of the 500 million data.
Why relabel method work? Because deep learning is statistic-based. Take classification as example. (In a broad sense, all the machine learning tasks can be viewed as classification.) If there are three very similar data (data-1/data-2/data-3) in total, which labels are class-A/class-A/class-B. Then the trained model will probably predict class-A for data-3. We assume that data-3 is wrong labeled to class-B by human, because more people label its similar data to class-A. If we do not correct data-3, the model prediction for new data that is the most similar to data-3 will be class-B, which is wrong. The new data is more similar to data-3 than data-1/data-2.
The cost of annotation time is crucial for deep learning tasks based on manually labeled data. If there is not enough labeling manpower, we must find ways to reduce the amount of data that needs to be labeled. If we can reduce the amount of data to be labeled to a level that a single programmer can handle, then we do not need an additional labeling team.
7. Conclusion
Human interacts with environment and learns from the feedback from environment to correct human’s own error. Base on the human’s correction idea, we design a learning framework to inject the information of human’s correction into the deep model. The experiment result shows our idea works. For further improvement, we will try to relabel the data which top-1 predicted score and top-2 predicted score are very close. It means that the model can hardly classify these data and the dataset contains noisy data here. We will combine relabel method and other noisy data detection methods \cite{ref16,ref17,ref18}, and try to find the most efficient method. Our idea can apply to a broad set of deep learning industry applications.
References
\bibitem{ref1}
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
\bibitem{ref2}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref3}
Wang A, Singh A, Michael J, et al. GLUE: A multi-task benchmark and analysis platform for natural language understanding[J]. arXiv preprint arXiv:1804.07461, 2018.
\bibitem{ref4}
Kingma D P, Ba J. Adam: A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
\bibitem{ref5}
Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. The journal of machine learning research, 2014, 15(1): 1929-1958.
\bibitem{ref6}
Xie Q, Dai Z, Hovy E, et al. Unsupervised data augmentation for consistency training[J]. arXiv preprint arXiv:1904.12848, 2019.
\bibitem{ref7}
Berthelot D, Carlini N, Goodfellow I, et al. Mixmatch: A holistic approach to semi-supervised learning[J]. arXiv preprint arXiv:1905.02249, 2019.
\bibitem{ref8}
Sohn K, Berthelot D, Li C L, et al. Fixmatch: Simplifying semi-supervised learning with consistency and confidence[J]. arXiv preprint arXiv:2001.07685, 2020.
\bibitem{ref9}
Berthelot D, Carlini N, Cubuk E D, et al. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring[J]. arXiv preprint arXiv:1911.09785, 2019.
\bibitem{ref10}
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
\bibitem{ref11}
Northcutt C G, Wu T, Chuang I L. Learning with confident examples: Rank pruning for robust classification with noisy labels[J]. arXiv preprint arXiv:1705.01936, 2017.
\bibitem{ref12}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
\bibitem{ref13}
Guo, Tong (2022): Re-Label By Data Pattern For Knowledge Driven Deep Learning. TechRxiv. Preprint. https://doi.org/10.36227/techrxiv.20485917.v7
\bibitem{ref14}
Northcutt C, Jiang L, Chuang I. Confident learning: Estimating uncertainty in dataset labels[J]. Journal of Artificial Intelligence Research, 2021, 70: 1373-1411.
\bibitem{ref15}
Zha D, Bhat Z P, Lai K H, et al. Data-centric artificial intelligence: A survey[J]. arXiv preprint arXiv:2303.10158, 2023.
\bibitem{ref16}
Hendrycks D, Gimpel K. A baseline for detecting misclassified and out-of-distribution examples in neural networks[J]. arXiv preprint arXiv:1610.02136, 2016.
\bibitem{ref17}
Kuan J, Mueller J. Model-agnostic label quality scoring to detect real-world label errors[C]//ICML DataPerf Workshop. 2022.
\bibitem{ref18}
Yu C, Ma X, Liu W. Delving into noisy label detection with clean data[C]//International Conference on Machine Learning. PMLR, 2023: 40290-40305.