Answering High-precision Problems for LLMs by Combining Text2code
Answering High-precision Problems for LLMs by Combining Text2code
Abstract
The current large language models (LLMs) mainly lacks this capability: answering high-precision questions/prompts. LLMs is actually a powerful fuzzy memory system that makes it difficult to answer high-precision questions. The result of code execution is a kind of high-precision answer. And expert system applications need to answer these kinds of questions. In this paper, to solve the above problem, We propose a design of LLMs combined with the text2code approach.
Keywords
Deep Learning, Text-To-Code, Expert System, Large Language Models
1. Introduction
Transformers-based models \cite{ref10} become the best models in most deep learning \cite{ref2} tasks. The transformers-based models also have the extremely excellent storage capabilities \cite{ref6,ref7,ref8}. Data centric methods \cite{ref9} \cite{ref11} \cite{ref12} become the main methods to improve model performance. These data-centric methods become the cornerstones of industrial level NLP system. On the other hand, reward-based methods \cite{ref13} formulate the world into a reward based framework. And we need a lot of engineering works to make a reward based closed-loop system.
Highly accurate predictions by AI system, broadly speaking, imply answers that surpass those of humans, such as AlphaGo \cite{ref16}. From another perspective, AlphaGo can surpass humans because for each input of the model, there is a 100% correct answer as the target label. Humans may make mistakes such as 1% when playing Go.
The development of LLMs/ChatGPT has made it possible to build more advanced expert systems. Current LLMs can be viewed as an AI system with strong fuzzy memory capabilities, based on the Turing computer architecture. As an expert system, Current LLMs lacks the ability to answer high-precision questions, such as code execution results. The examples are shown in Table 1 and Table 2.
In this paper we propose a design of AI system, called LLM-text2code system, that try to answer the high-precision questions for LLMs more accurately.
The LLM-text2code system has these modules:
1) LLMs that is pretrained on text and code.
2) An intent recognition module that determines whether to return code execution results or only natural language results.
3) A final answer generation model to combine the results of code execution and natural language results into a final answer.


2. Related Work
There are great code-LLM works \cite{ref1,ref3,ref4,ref5,ref14,ref15} that are pretrained on code and text. Our paper presents some contributions more from a perspective of applications such as expert system.
3. The LLM-text2code System
In this section we illustrate the detail of our design.
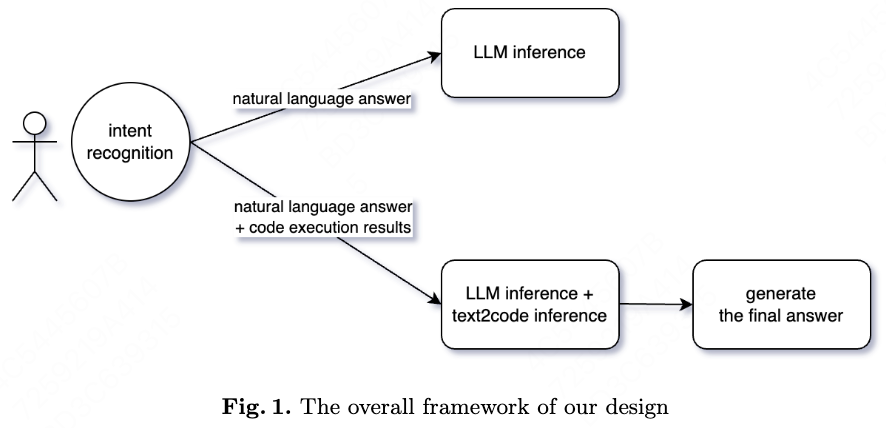
3.1 Common LLMs Module
This module includes natural language generation model and natural language to code generation model.
3.2 Intent Recognition Module
This module determines whether to use the text2code module or not. If the user only needs a relatively vague answer, we can just return the results of the text, without code execution results.
3.3 Answers Mixing Module
This module assembles the results of code execution and natural language intermediate results into a final result.
4. Discussion
The text2code approach has a lot of potential, because, in fact, all natural languages have their logical forms. We can design specific code for the application, for example SQL is a kind of code for the specific database-based application.
Letting LLMs to memorise all the correct answers is very time-consuming and difficult, so joining text2code methods with LLMs is a promising way forward.
Returning fuzzy answers for fuzzy questions by LLMs and returning high-precision answers for high-precision questions by text2code are ideal solution.
5. Future Works
In our design, we view that data is part of the code. That is, models trained on the data, viewed as part of the code.
In the future, we will try to design an AI system contains more modules: code2text, code2code, to build a better expert system like a better AI-doctor/AI-lawyer/AI-teacher:
github.com/guotong1988/code2image_LM_image2code
github.com/guotong1988/code2text_LLM_text2code
References
\bibitem{ref1}
Roziere B, Gehring J, Gloeckle F, et al. Code llama: Open foundation models for code[J]. arXiv preprint arXiv:2308.12950, 2023.
\bibitem{ref2}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref3}
Chen M, Tworek J, Jun H, et al. Evaluating large language models trained on code[J]. arXiv preprint arXiv:2107.03374, 2021.
\bibitem{ref4}
Lewkowycz A, Andreassen A, Dohan D, et al. Solving quantitative reasoning problems with language models, 2022[J]. URL https://arxiv. org/abs/2206.14858, 2022.
\bibitem{ref5}
Chowdhery A, Narang S, Devlin J, et al. Palm: Scaling language modeling with pathways[J]. Journal of Machine Learning Research, 2023, 24(240): 1-113.
\bibitem{ref6}
Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
\bibitem{ref7}
Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
\bibitem{ref8}
Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
\bibitem{ref9}
Zha D, Bhat Z P, Lai K H, et al. Data-centric artificial intelligence: A survey[J]. arXiv preprint arXiv:2303.10158, 2023.
\bibitem{ref10}
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
\bibitem{ref11}
OpenAI (2023). GPT-4 Technical Report. ArXiv, abs/2303.08774.
\bibitem{ref12}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
\bibitem{ref13}
Silver, David , et al. "Reward is enough." Artificial Intelligence 299.
\bibitem{ref14}
Anil R, Dai A M, Firat O, et al. Palm 2 technical report[J]. arXiv preprint arXiv:2305.10403, 2023.
\bibitem{ref15}
Zhang Z, Chen C, Liu B, et al. Unifying the perspectives of nlp and software engineering: A survey on language models for code[J]. arXiv preprint arXiv:2311.07989, 2023.
\bibitem{ref16}
Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. nature, 2016, 529(7587): 484-489.