Auto Self-Correct ChatGPT
Auto Self-Correct ChatGPT
Abstract
We propose Auto Self-Correct ChatGPT (ASC-GPT) to solve the problem to let human teach ChatGPT to refresh/expand ChatGPT’s knowledge automatically. The core idea of our method is: Correcting/Teaching the ChatGPT’s knowledge equals to editing the related data in the whole train-dataset of ChatGPT’s policy model. We propose the procedures to implement our idea and discuss the reasons why we design these procedures.
1. Introduction
Large language models (LLM) like ChatGPT and GPT-4 [1] are extremely powerful in multi-task NLP learning. The transformers[8] show great ability to learn the text context and store the pre-training information. LLM also improves the development of continuous learning, which means LLM can learn new data without forgeting the old data. The problem now is that ChatGPT contains some knowledge that is not aligned to human requirements. Our work try to solve the this problem that let human teach ChatGPT to correct the alignment automatically. Our work contains these contributions:
-
We try to solve the problem to let human teach ChatGPT, based on the ChatGPT’s ability to chat with human.
-
We try to correct the train-dataset of ChatGPT’s policy model by ChatGPT itself automatically, while ChatGPT is chating with human.
-
We discuss some possible details to implement our goal.
2. Method
2.1 Procedures
2.1.1 Train Policy Model
The procedures for training policy model is shown in Fig 1.

In Fig 1. the three steps are:
Step-1. This step is same to InstructGPT’s [4] first step. In this step, we use the init train-dataset to train/fine-tune the first policy model, based on the pre-trained language model [5].
Step-2. This step is different to InstructGPT’s second step. This step do not have the reward part of InstructGPT, because we think the high quality data is the most important. The high quality model’s outputs are selected by human and merged to the init train-dataset.
Step-3. Using the self-predict and re-label method [3] to find the potential wrong/noise data for human to check and fix. In actual operation, this correction step can be a choice question for labeling people. The labeling people chooses the best result from model generation sentences and origin training sentence. Then we get a better train-dataset to train a better policy model. This step can be done for several times. The self-predict and re-label method has been verified to improve the data quality and model performance to 97% in [3].
2.1.2 Teach Policy Model
The procedures for teaching policy model new knowledge is shown in Fig 2.
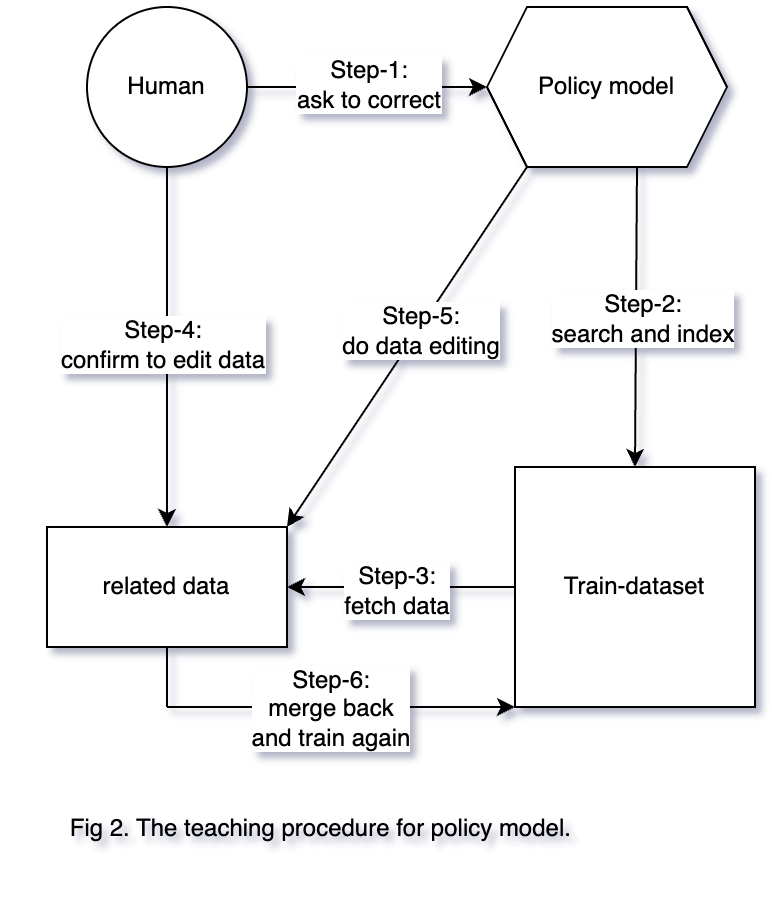
In Fig 2. the six steps are:
Step-1. Human inputs a prompt to policy model and find a wrong response. Then human asks policy model to correct. The detail interaction operation for the wrong-find step can be chat-based or button-based.
Step-2. Policy model call the search system to find the related data corresponding to the prompt of Step-1. In this step, policy model transforms natural language to code to call the search system. It is a similar text search problem here. In this work, we use keyword-based search algorithm.
Step-3. The search system fetch the related data from train-dataset. Then the related data is listed for human. As the search system uses the keyword-based searching algorithm, we first split the prompt-response-pair of Step-1 to sub-strings/keywords. Then we search the sub-strings in the train-dataset.
Step-4. Human confirms and inputs the right data to replace/edit the fetched related data. In this step, the policy model can also recommend some candidate ways to fix the data.
Step-5. We process human’s input data to the exact format that same to the train-dataset.
Step-6. Based on the data indexes of search system, the new data is merged/replaced into the train-dataset. The policy model is trained again.
2.2 Modules
The ASC-GPT contains these sub-modules:
2.2.1 Search System
The keyword-based coded search system that can find the related data in the whole train-dataset of policy model. Policy model interacts with this system, following the instructions from human. For example, human find a wrong response of policy model. The search system split the corresponding prompt-response-pair to sub-strings. Then the search system takes the sub-strings as queries. The search system can also be implemented by policy model: We input the prompt that ask policy model to find the most similar data in its own train-dataset.
2.2.2 Policy Model
Human labeled the init chating train-dataset that can train policy model to chat with human. The policy model can accept these human instructions:
-
Human instructions that ask policy model to call the search system to find the related data. The policy model transforms natural language to code to call the search system.
-
Human instructions that confirm to do the editing of related data, when human think ChatGPT’s response is wrong. Then the policy model transforms natural language to code to call the data editing system.
2.2.3 Data Editing Module
This module transforms the new human-inputed knowledge to the exact format that is same to the train-dataset. It is an editing/replacing/adding coded system for related old data that is fetched from train-dataset. Human decides what to do with the new-inputed data: Editing the old data by new data, replacing the old data by new data, or merging the new data to the old data. Policy model interacts with this system, using the knowledge from human and call this system to correct the data in train-dataset.
3. Discussion
In this section we discuss the reasons why we design the procedures.
Similar Text Search
We think the model inference equals to finding the most similar prompt-response-pair in train-dataset. So fixing the model knowledge equals to fixing the its most similar related data in train-dataset.
Why do we choose sub-strings keyword-based to implement similar text search? If we split the target prompt-response-pair to sub-strings, the train-dataset should contain the same part of sub-strings or patterns somewhere.
Without Reward model
Our mothod removes the reward model of InstructGPT [4]. Because we think the most important thing is the train-dataset and its quality. We use the self-predict and re-label method [3] to improve the data quality.
4. Related Work
Pre-trained language models [6][7] store the text context for the downstream tasks and improve their performance.
As the model size becomes larger, GPT-3[5] achieves strong performance on many NLP datasets and demonstrate that scaling up language models greatly improves task-agnostic, few-shot performance. ChatGPT [1] fine-tunes with the alignment dataset, based on GPT-3, shows great performance on real world NLP tasks.
Auto-GPT [2] proposes the goal that attempts to make GPT-4 fully autonomous, which is a great work and do not conflict to our method. Auto-GPT try to solve the problem that let ChatGPT interact with the internet. Our method focus on the problem that let human teach ChatGPT.
[9]’s methods aim to update LLMs in a way that sidesteps the computational burden associated with training a wholly new model.
5. Conclusion
We propose Auto Self-Correct ChatGPT to solve the problem that allow human to teach ChatGPT/policy-model to refresh/expand ChatGPT’s knowledge. The core idea of our method is: Editing the policy model’s knowledge equals to editing the related data in the whole train-dataset of policy model.
References
[1] OpenAI. 2023. Gpt-4 technical report.
[2] https://github.com/Significant-Gravitas/Auto-GPT
[3] Guo T. The Re-Label Method For Data-Centric Machine Learning[J]. arXiv preprint arXiv:2302.04391, 2023.
[4] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
[5] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[6] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[7] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J]. 2018.
[8] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[9] Yao Y, Wang P, Tian B, et al. Editing Large Language Models: Problems, Methods, and Opportunities[J]. arXiv preprint arXiv:2305.13172, 2023.