Automatic Label Error Correction
Automatic Label Error Correction
Abstract
In the previous works, we verify that manual re-labeling the training data that model prediction do not equal to the manual label, improve the accuracy at dev dataset and human evaluation. But manual re-labeling requires a lot of human labor to correct the noisy data in the training dataset. We think that the noisy data is the training data that model prediction and manual label is not equal. To solve this problem, we propose the randomly re-setting method that automaticly improve the accuracy at dev dataset and human evaluation. The core idea is that, we randomly re-set all the noisy data to model prediction or the manual label. All the noisy data means the noisy data in training dataset and dev dataset. We use the highest accuracy of dev dataset in the all possible randomly re-setted dev datasets, to judge the quality of randomly re-setted training datasets. The motivation of randomly re-setting is that the best dataset must be in all randomly possible datasets.
1. Introduction
In recent years, deep learning \cite{ref1} model have shown significant improvement on natural language processing (NLP), computer vision (CV) and speech processing technologies. However, the model performance is limited by the human-labeled data quality. The main reason is that the human-labeled data has a certain number of noisy data. Previous work \cite{ref2} has propose the method to find the noisy data and manually correct the noisy data. In this paper, we first review the method we achieve more than 90 score in dev dataset and more than 95 score under human evaluation, then we illustrate our method that randomly re-setting and the best dataset selection. The problem with manual re-labeling is that it consumes a lot of labor. In order to solve this problem, we propose automatic re-labeling method.
In summary, our contributions include:
1) In order to solve the problem that manual re-labeling consumes a lot of labor to correct the noisy data, we propose automatic re-labeling method to find the best dataset in the possible candidate datasets.
2) We propose the method that constructs the candidate datasets by randomly setting the labels to predicted label or human label. And we propose the method that using accuracy of dev dataset to find the best dataset. Because we already verify that the improved dataset exists in the candidate datasets.
3) The code is at https://github.com/guotong1988/Automatic-Label-Error-Correction
2. Background
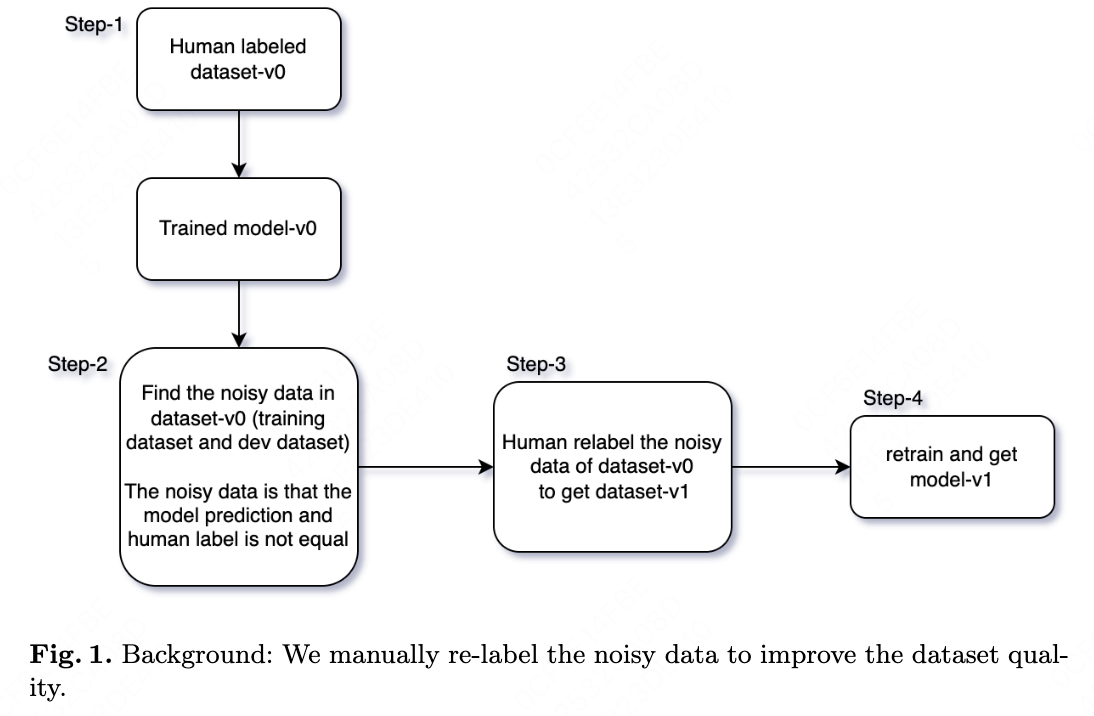
In previous work \cite{ref2}, we illustrate the method of manual correction in these steps:
Step-1. We assume it is a classification task. We have a human-labeled dataset-v0 (training dataset and dev dataset). We train a deep model upon dataset-v0 and get model-v0.
Step-2. Using model-v0 to predict the classification labels for dataset-v0 (training dataset and dev dataset). If the predicted labels of dataset-v0 do not equal to the human labels of dataset-v0, we think they are the noisy data.
Step-3. We label the noisy data (training dataset and dev dataset) again by human, while given the labels of model and last label by human as reference. Then we get dataset-v1
Step-4. We train on dataset-v1 and get model-v1.
We loop these re-labeling noisy data steps and get the final dataset and final model.
3. Auto Re-label
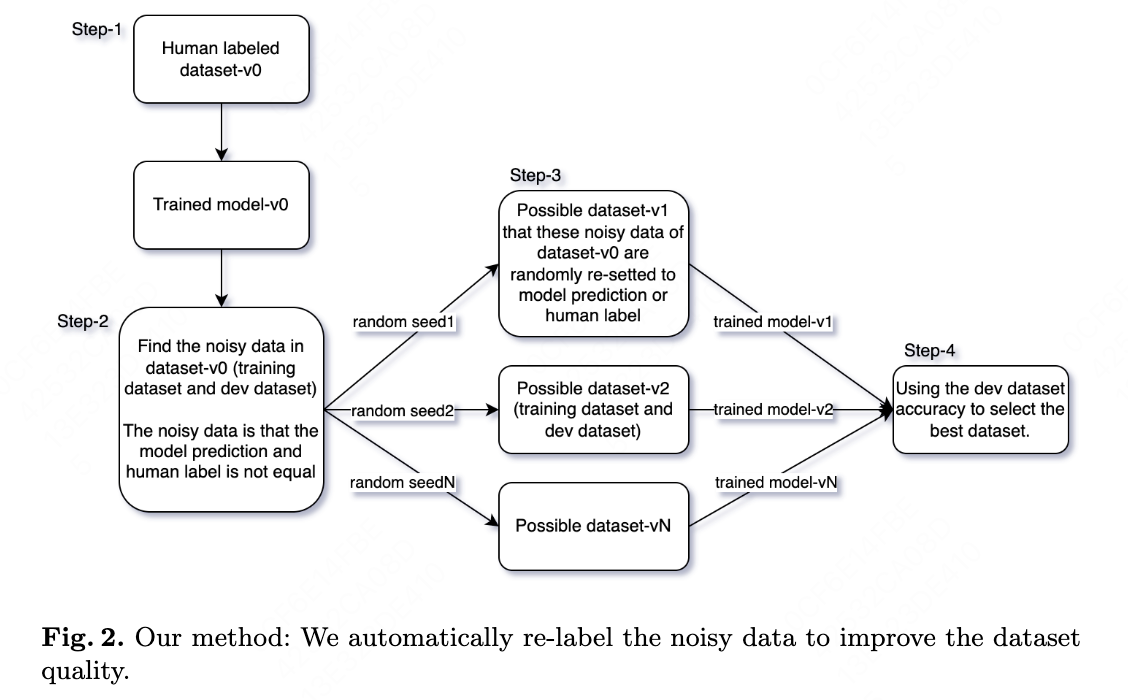
Our automatic noisy data correction method contains 4 steps:
Step-1. We assume it is a classification task. We have a human-labeled dataset-v0 (training dataset and dev dataset) and a model-v0 that is trained on dataset-v0’s training dataset.
Step-2. Using model-v1 to predict the classification label for dataset-v0. If the predicted label of dataset-v0 (training dataset and dev dataset) do not equal to the human label of dataset-v0, we think they are the noisy data.
Step-3. We randomly re-set each of the noisy data label to model predicted label or human label. Each setting possibility becomes a new dataset with training + dev dataset. Then we get $2^N$ datasets (dataset-v1, dataset-v2 … dataset-vN) and $2^N$ models (model-v1, model-v2 … model-vN).
Step-4. We use dev dataset accuracy to select the best dataset from all the $2^N$ datasets. The best dataset becomes the new dataset-v0.
4. Discussion
From the noisy data correction point of view, the noisy data that model prediction and manual label is not equal. So any label editing to these noisy data may be the improvement to the dataset quality.
It seems that our method definitely improves the accuracy on the dev dataset, but not necessarily the accuracy of the manual evaluation. But based on our previous work \cite{ref2}, the accuracy of the dev dataset and the accuracy of the human evaluation are linearly correlated.
We did the manual re-labeling experiments in \cite{ref2}, we verify that the improved dataset exists in all 2^N possible datasets.
5. Experiments On Open Datasets
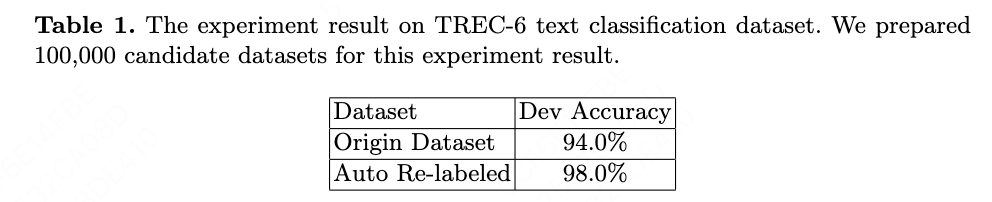
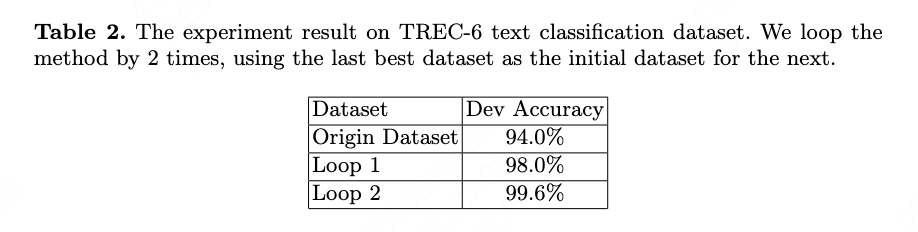
The experiment result on TREC-6 text classification dataset is shown in Table \cite{table1} and Table \cite{table2}. The model to fine-tune/train is the pre-trained BERT \cite{ref3,ref4}, which has 12-layer and 768 hidden size.
6. Related Work
Data-centric \cite{ref5} approach which focuses on label quality by characterizing and identifying label errors in datasets.
Label error correction or noise data correction\cite{ref6,ref7,ref8,ref9,ref10,ref11,ref12} is to correct the error labeled data to improve the dataset quality.
\cite{ref6} uses the label relationships to correct label error without human annotation. \cite{ref7} corrected the original loss value by introducing the model’s prediction labels into loss function. \cite{ref8} proposes the self-error-correcting CNN learning framework to deal with the problem of noisy labels and demonstrates that the model is robust to label noise even up to 80% proportion. \cite{ref9} presents a human/machine learning method for cleaning training data of label noise when an alternate, high confidence labeling source is available. \cite{ref10} described a grammatical error annotation toolkit designed to automatically annotate parallel error correction data with explicit edit spans and error type information. \cite{ref11} uses a novel algorithm termed adaptive voting noise correction to precisely identify and correct the potential noisy labels. \cite{ref12} proposes a novel algorithm that corrects the labels based on the noisy classifier prediction.
Our method is different from the above works. We first verify that human re-labeling can improve the dataset quality. Then we propose our method that can automatically do the re-labeling without human annotation.
7. Conclusion
In previous works, we manually re-label the noisy data to improve the dataset quality. In this paper, we propose the method to automatically re-label the noisy data to improve the dataset quality. The experimental results and theoretical analysis verify our idea: The best re-labeled dataset exists in the all possible candidate datasets.
References
\bibitem{ref1}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref2}
Guo T. The Re-Label Method For Data-Centric Machine Learning[J]. arXiv preprint arXiv:2302.04391, 2023.
\bibitem{ref3}
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
\bibitem{ref4}
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
\bibitem{ref5}
Zha D, Bhat Z P, Lai K H, et al. Data-centric artificial intelligence: A survey[J]. arXiv preprint arXiv:2303.10158, 2023.
\bibitem{ref6}
Cui Z, Zhang Y, Ji Q. Label error correction and generation through label relationships[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(04): 3693-3700.
\bibitem{ref7}
Tong F, Liu Y, Li S, et al. Automatic error correction for speaker embedding learning with noisy labels[C]//Proc. Interspeech. 2021.
\bibitem{ref8}
Liu X, Li S, Kan M, et al. Self-error-correcting convolutional neural network for learning with noisy labels[C]//2017 12th IEEE International Conference on Automatic Face \& Gesture Recognition (FG 2017). IEEE, 2017: 111-117.
\bibitem{ref9}
Rebbapragada U, Brodley C E, Sulla-Menashe D, et al. Active label correction[C]//2012 IEEE 12th International Conference on Data Mining. IEEE, 2012: 1080-1085.
\bibitem{ref10}
Bryant C J, Felice M, Briscoe E. Automatic annotation and evaluation of error types for grammatical error correction[C]. Association for Computational Linguistics, 2017.
\bibitem{ref11}
Zhang J, Sheng V S, Li T, et al. Improving crowdsourced label quality using noise correction[J]. IEEE transactions on neural networks and learning systems, 2017, 29(5): 1675-1688.
\bibitem{ref12}
Zheng S, Wu P, Goswami A, et al. Error-bounded correction of noisy labels[C]//International Conference on Machine Learning. PMLR, 2020: 11447-11457.