Re-Label By Data Pattern For Controllable Deep Learning
Re-Label By Data Pattern For Controllable Deep Learning
Abstract
In industry deep learning application, we should fix the badcase by human evaluation after we achieve more than 95% accuracy at dev dataset. The badcase reason is from the wrong rule/knowledge of human labeling and will cause low accuracy under human evaluation. In this paper, we propose the pattern-based method to fix the badcase for industry application inference. We propose the pipeline to solve the problem and improve the accuracy of human evaluation. The experiment results verify our idea, which means label-edit/data-edit is the method to implement controllable deep learning application.
Keywords
Deep Learning, Pattern Recognition, Fuzzy Matching, Similar Search
1. Introduction
In industry deep learning \cite{ref1} application, we use the re-label method\cite{ref2} to achieve more than 95% accuracy at dev dataset. But under human evaluation for industry application inference, the accuracy is only around 90%-94%. The reason for this problem can be found on the badcase review. In the badcase review, we find that the badcase is caused by wrong rule/knowledge of human labeling. In order to fix the badcase of training data. we propose the pattern-based re-label pipeline. The intuition is that the badcase prediction data should contain the same pattern in the training data. Take text classification as example, it means the badcase prediction data contains the same tokens in the training data. So we could retrieve all the training text which contains the same pattern/tokens of evaluation data and re-label them.
In this paper, knowledge-driven means the knowledge for labeling when we teach the human how to label. Our method is a kind of human-in-the-loop which means we refresh the knowledge for human to re-label the data. It means we implement controllable deep learning application by label-edit.
2. Method
In this section, we propose the pipeline to improve the human evaluation accuracy.
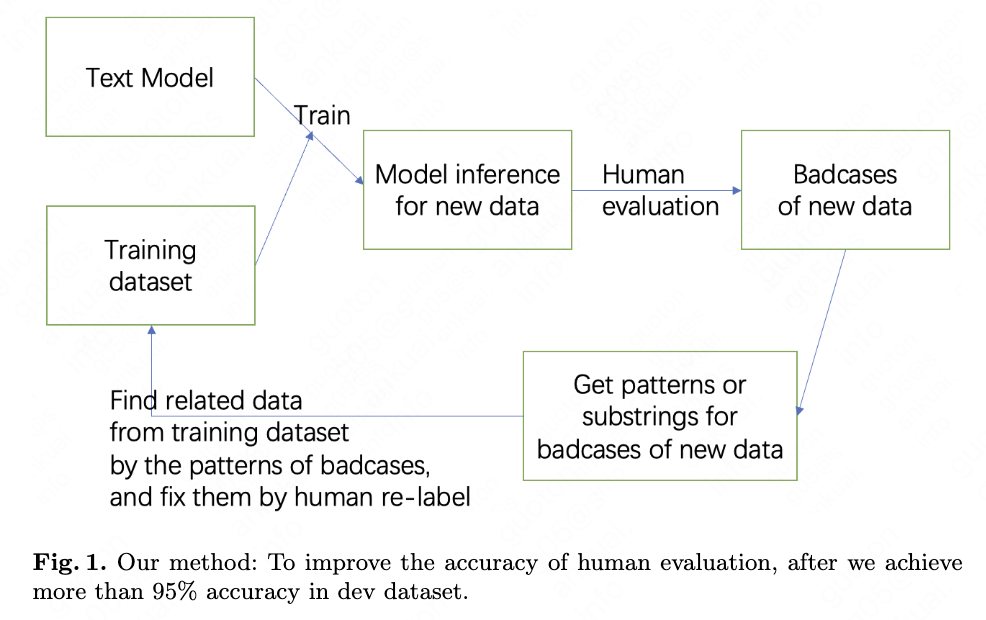
Step-1. Based on the human-labeled training dataset, we train a deep model and predict for industry application dataset. Human evaluate the current deep model prediction dataset and find the badcase patterns. Take text classification task as example, the pattern is the tokens from the badcase prediction text. For computer vision task, we use the embedding from the badcase prediction image to do the similarity search in training dataset.
If there are no training data that is recognised by badcase patterns, we newly label the real application data that is recognised by badcase patterns and merge to the training data. And then we can also get more than 95% accuracy in dev dataset by \cite{ref6} method.
Step-2. Re-set the labeling rule/knowledge for human. Then the knowledge-refreshed human re-label the training data that is recognised by badcase patterns of Step-1. When re-labeling, we can provide the results of the last annotation and model prediction as references. Then we train to get a new version of current deep model.
In this step, the range of to-label targets can be simplified, because the to-label data is recognised by badcase patterns and is limited to a smaller range of distribution. So we reduce labeling difficulty by reduce the to-label targets range, which also improves the human labeling accuracy.
Loop Step-1 and Step-2. Back to last Step-1 and re-evaluate the last Step-2 model’s predictions and find the new badcase patterns.
3. Experimental Results
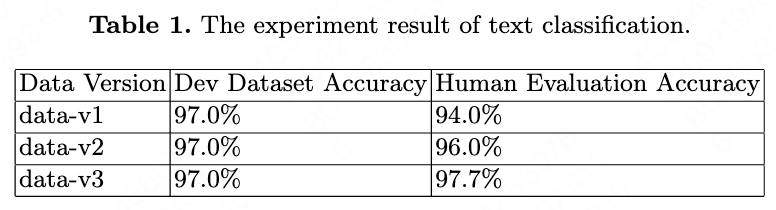
In the section, we describe the experiment results. Take our text classification task as example. The result is shown in Table 1. In Table 1, data-v1 means the origin training data. And data-v2 and data-v3 means the training data after we use our method for 2 loops, based on data-v1.
4. Related Work
There are works that inject knowledge into deep model. But they are different from our work. They focus on model-centric part, but our method focuses on the human-in-the-loop labeling data-centric part.
4.1 Rule-enhanced Text2Sql
In the text2sql task, there is work\cite{ref3} that injects external entity type-info/knowledge into deep model. There is work \cite{ref4} that inject database design rules/knowledge into deep model. These works give external information that can not be captured by an end-to-end deep model.
4.2 Keyword-enhanced NER
In the named-entity-recognise task, there is work\cite{ref5} that injects the entity dictionary into deep model. This work give more information for the deep model if the entities of training data is similar to test data.
4.3 ChatGPT
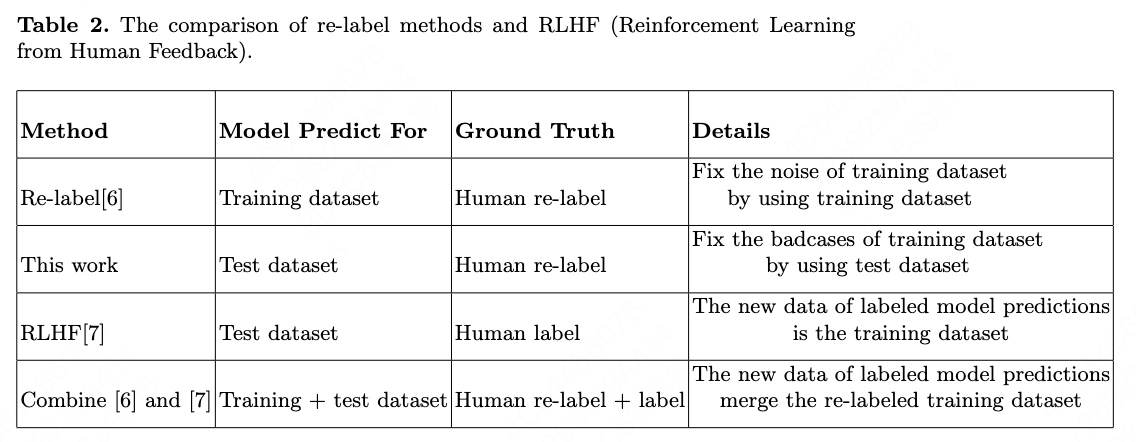
The work \cite{ref7} of OpenAI use model predictions for human as new data to label. The model predictions are actually based on the training dataset. Our work do not have the reward model of \cite{ref7}, the differnce between reinforcement learning from human feedback(RLHF) and our re-label method is that RLHF focus on using the model predictions as training dataset of reward model, and our re-label method focus on correcting the origin training dataset of policy model. Also, RLHF corrects the policy by reward model, which is same to correct all the related data/labels in training dataset of policy model. Human feedback’s goal is to fix the wrong data in policy model’s dataset.
5. Discussion
The similar search method can also apply to quality inspection of the human-labeled dataset: We get a human-labeled dataset, and then we check and find a small set of error-labeled data. Then we search more similar data of error-labeled data for human to correct them, so that it can reduce the range of human-labeled dataset to check and correct.
5.1 Motivation
Take text classification as example, if the model predicted result is wrong for a new evaluation data. Then the new evaluation data’s most similar data in the training dataset must be wrong.
Fixing the wrong model predicted results for a new evaluation data, means fixing the evaluation data’s most similar data in the training dataset. Editing the model predicted results for a new evaluation data, means editing the evaluation data’s most similar data in the training dataset.
6. Conclusion
In this paper, we solve the problem of the low accuracy under human evaluation after we achieve good accuracy of dev dataset. We propose the pipeline: First, we find the badcase in the prediction data and summarize the right knowledge for human labeling. Second, we summarize the pattern from prediction badcase data and re-label the training data which match the pattern. Loop this pipeline means we inject the right knowledge/rule to the deep model by re-label the training data retrieved by pattern from badcase prediction data. The experiment results verify our idea. Our idea can apply to a broad set of deep learning industry applications.
References
\bibitem{ref1}
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25: 1097-1105.
\bibitem{ref2}
Guo T. Learning From How Humans Correct[J]. arXiv preprint arXiv:2102.00225, 2021.
\bibitem{ref3}
Yu T, Li Z, Zhang Z, et al. Typesql: Knowledge-based type-aware neural text-to-sql generation[J]. arXiv preprint arXiv:1804.09769, 2018.
\bibitem{ref4}
Guo T, Gao H. Content enhanced bert-based text-to-sql generation[J]. arXiv preprint arXiv:1910.07179, 2019.
\bibitem{ref5}
https://github.com/guotong1988/Chinese-NER-InjectDictRule
\bibitem{ref6}
Guo T. The Re-Label Method For Data-Centric Machine Learning[J]. arXiv preprint arXiv:2302.04391, 2023.
\bibitem{ref7}
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.